Data Wrangling with Pandas II#

Outline#
In this class we will talk more about:
“Tips and tricks” for working with
pandasCombining Datasets: Concat and Append
Visualizing Data using
seabornandpandasAdditional Notes you may found helpful
Useful packages: Numpy and Random#
Useful packages: Numpy and Random#
Generating Random numbers using the random package
Using numpy
import random
import numpy as np
# Generate a random integer (!) between a and b (here a=0, b=50)
random.randint(a=0, b=50)
50
# Generate a random number (int) (!) between a and b (here a=0, b=50) in steps.
# For e.g., an "even number"
random.randrange(0, 50, step=2)
46
# Generate a random number (!) between a and b (here a=0, b=50) in "step".
# Can use tricks to divide.
random.randrange(0, 100, step=1) / 10
6.3
# for loop to generate 10 random numbers
for i in range(10):
print(random.randrange(5, 50))
28
46
21
28
23
37
34
13
23
9
# for loop to generate 10 random numbers
# and store into a list
rints = []
for i in range(10):
rints.append(random.randrange(5, 50))
rints
[23, 16, 45, 11, 10, 41, 26, 31, 8, 10]
# list comprehension to generate 10 random numbers
[random.randrange(5, 50) for i in range(10)]
[5, 30, 6, 41, 25, 6, 38, 14, 19, 46]
# list comprehension to generate 10 random numbers
# and store into a list
rints2 = [random.randrange(5, 50) for i in range(10)]
rints2
[28, 18, 15, 42, 37, 18, 11, 16, 42, 25]
np.arange(5, 50)
array([ 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21,
22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38,
39, 40, 41, 42, 43, 44, 45, 46, 47, 48, 49])
rints3 = np.arange(5, 50)
rints3
array([ 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21,
22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38,
39, 40, 41, 42, 43, 44, 45, 46, 47, 48, 49])
random.choice(rints3)
24
# another way
for i in range(10):
print(random.choice(rints3))
13
28
10
12
35
49
37
37
14
6
Seeds#
What if you want the same random number every time? (Trust me, it’s useful!)
You can set the seed.
# Setting a seed to a specific number
random.seed(3.1415)
random.randint(0, 500)
18
random.seed(1000)
random.randint(50,100)
99
random.randint(50,100)
77
Numpy#
# Generate 10 random floats (!) between 0 and 1
# Yes, numpy also has a random number generator
np.random.rand(10)
array([0.65584237, 0.93588617, 0.81592433, 0.57357308, 0.32367484,
0.99859453, 0.21846279, 0.39811104, 0.54377178, 0.31657825])
# store that into a variable
r = np.random.rand(10)
# Check the type:
type(r)
numpy.ndarray
What is a numpy array?#
Let’s find out!
# but numpy is a lot more useful, it is the primary tool used for scientific computing!
test_list = [5,4,6,7,8]
type(list(np.array(test_list)))
list
Working with Pandas to load data#
import pandas as pd
Always use RELATIVE paths!!#
pwd
'/home/runner/work/data301_course/data301_course/notes/week05/Class5B'
!ls data/
chord-fingers1.csv state-abbrevs.csv state-population.csv
chord-fingers2.csv state-areas.csv
What if your data is not UTF-8 encoded?#
(Hint: You will get a UnicodeDecodeError)
url = "http://nfdp.ccfm.org/download/data/csv/NFD%20-%20Area%20burned%20by%20cause%20class%20-%20EN%20FR.csv"
dataset = pd.read_csv(url)
---------------------------------------------------------------------------
UnicodeDecodeError Traceback (most recent call last)
Cell In[24], line 3
1 url = "http://nfdp.ccfm.org/download/data/csv/NFD%20-%20Area%20burned%20by%20cause%20class%20-%20EN%20FR.csv"
----> 3 dataset = pd.read_csv(url)
File /opt/hostedtoolcache/Python/3.10.13/x64/lib/python3.10/site-packages/pandas/io/parsers/readers.py:948, in read_csv(filepath_or_buffer, sep, delimiter, header, names, index_col, usecols, dtype, engine, converters, true_values, false_values, skipinitialspace, skiprows, skipfooter, nrows, na_values, keep_default_na, na_filter, verbose, skip_blank_lines, parse_dates, infer_datetime_format, keep_date_col, date_parser, date_format, dayfirst, cache_dates, iterator, chunksize, compression, thousands, decimal, lineterminator, quotechar, quoting, doublequote, escapechar, comment, encoding, encoding_errors, dialect, on_bad_lines, delim_whitespace, low_memory, memory_map, float_precision, storage_options, dtype_backend)
935 kwds_defaults = _refine_defaults_read(
936 dialect,
937 delimiter,
(...)
944 dtype_backend=dtype_backend,
945 )
946 kwds.update(kwds_defaults)
--> 948 return _read(filepath_or_buffer, kwds)
File /opt/hostedtoolcache/Python/3.10.13/x64/lib/python3.10/site-packages/pandas/io/parsers/readers.py:611, in _read(filepath_or_buffer, kwds)
608 _validate_names(kwds.get("names", None))
610 # Create the parser.
--> 611 parser = TextFileReader(filepath_or_buffer, **kwds)
613 if chunksize or iterator:
614 return parser
File /opt/hostedtoolcache/Python/3.10.13/x64/lib/python3.10/site-packages/pandas/io/parsers/readers.py:1448, in TextFileReader.__init__(self, f, engine, **kwds)
1445 self.options["has_index_names"] = kwds["has_index_names"]
1447 self.handles: IOHandles | None = None
-> 1448 self._engine = self._make_engine(f, self.engine)
File /opt/hostedtoolcache/Python/3.10.13/x64/lib/python3.10/site-packages/pandas/io/parsers/readers.py:1723, in TextFileReader._make_engine(self, f, engine)
1720 raise ValueError(msg)
1722 try:
-> 1723 return mapping[engine](f, **self.options)
1724 except Exception:
1725 if self.handles is not None:
File /opt/hostedtoolcache/Python/3.10.13/x64/lib/python3.10/site-packages/pandas/io/parsers/c_parser_wrapper.py:93, in CParserWrapper.__init__(self, src, **kwds)
90 if kwds["dtype_backend"] == "pyarrow":
91 # Fail here loudly instead of in cython after reading
92 import_optional_dependency("pyarrow")
---> 93 self._reader = parsers.TextReader(src, **kwds)
95 self.unnamed_cols = self._reader.unnamed_cols
97 # error: Cannot determine type of 'names'
File parsers.pyx:579, in pandas._libs.parsers.TextReader.__cinit__()
File parsers.pyx:668, in pandas._libs.parsers.TextReader._get_header()
File parsers.pyx:879, in pandas._libs.parsers.TextReader._tokenize_rows()
File parsers.pyx:890, in pandas._libs.parsers.TextReader._check_tokenize_status()
File parsers.pyx:2050, in pandas._libs.parsers.raise_parser_error()
UnicodeDecodeError: 'utf-8' codec can't decode byte 0xe9 in position 8: invalid continuation byte
Demo#
Now what!?
Now we google it…
And according to this stack overflow page: we should try:
pd.read_csv(url, encoding='latin')
So let’s give it a shot:
pd.read_csv(url, encoding="latin")
# Works!!
| Year | Année | ISO | Jurisdiction | Juridiction | Cause | Origine | Area (hectares) | Data Qualifier | Superficie (en hectare) | Qualificatifs de données | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1990 | 1990 | AB | Alberta | Alberta | Human activity | Activités humaines | 2393.8 | a | 2393.8 | a |
| 1 | 1990 | 1990 | AB | Alberta | Alberta | Lightning | Foudre | 55482.6 | a | 55482.6 | a |
| 2 | 1990 | 1990 | AB | Alberta | Alberta | Unspecified | Indéterminée | 1008.8 | a | 1008.8 | a |
| 3 | 1990 | 1990 | BC | British Columbia | Colombie-Britannique | Human activity | Activités humaines | 40278.3 | a | 40278.3 | a |
| 4 | 1990 | 1990 | BC | British Columbia | Colombie-Britannique | Lightning | Foudre | 35503.5 | a | 35503.5 | a |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 1054 | 2021 | 2021 | PC | Parks Canada | Parcs Canada | Unspecified | Indéterminée | 42538.0 | e | 42538.0 | e |
| 1055 | 2021 | 2021 | PE | Prince Edward Island | Île-du-Prince-Édouard | Unspecified | Indéterminée | 0.1 | e | 0.1 | e |
| 1056 | 2021 | 2021 | QC | Quebec | Québec | Unspecified | Indéterminée | 49748.0 | e | 49748.0 | e |
| 1057 | 2021 | 2021 | SK | Saskatchewan | Saskatchewan | Unspecified | Indéterminée | 956084.0 | e | 956084.0 | e |
| 1058 | 2021 | 2021 | YT | Yukon | Yukon | Unspecified | Indéterminée | 118126.0 | e | 118126.0 | e |
1059 rows × 11 columns
What if your data is not comma-separated?#
chord1 = pd.read_csv("data/chord-fingers1.csv")
chord1.head()
---------------------------------------------------------------------------
ParserError Traceback (most recent call last)
Input In [160], in <cell line: 1>()
----> 1 chord1 = pd.read_csv("data/chord-fingers1.csv")
2 chord1.head()
File ~/.pyenv/versions/3.10.2/lib/python3.10/site-packages/pandas/util/_decorators.py:311, in deprecate_nonkeyword_arguments.<locals>.decorate.<locals>.wrapper(*args, **kwargs)
305 if len(args) > num_allow_args:
306 warnings.warn(
307 msg.format(arguments=arguments),
308 FutureWarning,
309 stacklevel=stacklevel,
310 )
--> 311 return func(*args, **kwargs)
File ~/.pyenv/versions/3.10.2/lib/python3.10/site-packages/pandas/io/parsers/readers.py:680, in read_csv(filepath_or_buffer, sep, delimiter, header, names, index_col, usecols, squeeze, prefix, mangle_dupe_cols, dtype, engine, converters, true_values, false_values, skipinitialspace, skiprows, skipfooter, nrows, na_values, keep_default_na, na_filter, verbose, skip_blank_lines, parse_dates, infer_datetime_format, keep_date_col, date_parser, dayfirst, cache_dates, iterator, chunksize, compression, thousands, decimal, lineterminator, quotechar, quoting, doublequote, escapechar, comment, encoding, encoding_errors, dialect, error_bad_lines, warn_bad_lines, on_bad_lines, delim_whitespace, low_memory, memory_map, float_precision, storage_options)
665 kwds_defaults = _refine_defaults_read(
666 dialect,
667 delimiter,
(...)
676 defaults={"delimiter": ","},
677 )
678 kwds.update(kwds_defaults)
--> 680 return _read(filepath_or_buffer, kwds)
File ~/.pyenv/versions/3.10.2/lib/python3.10/site-packages/pandas/io/parsers/readers.py:581, in _read(filepath_or_buffer, kwds)
578 return parser
580 with parser:
--> 581 return parser.read(nrows)
File ~/.pyenv/versions/3.10.2/lib/python3.10/site-packages/pandas/io/parsers/readers.py:1254, in TextFileReader.read(self, nrows)
1252 nrows = validate_integer("nrows", nrows)
1253 try:
-> 1254 index, columns, col_dict = self._engine.read(nrows)
1255 except Exception:
1256 self.close()
File ~/.pyenv/versions/3.10.2/lib/python3.10/site-packages/pandas/io/parsers/c_parser_wrapper.py:225, in CParserWrapper.read(self, nrows)
223 try:
224 if self.low_memory:
--> 225 chunks = self._reader.read_low_memory(nrows)
226 # destructive to chunks
227 data = _concatenate_chunks(chunks)
File pandas/_libs/parsers.pyx:805, in pandas._libs.parsers.TextReader.read_low_memory()
File pandas/_libs/parsers.pyx:861, in pandas._libs.parsers.TextReader._read_rows()
File pandas/_libs/parsers.pyx:847, in pandas._libs.parsers.TextReader._tokenize_rows()
File pandas/_libs/parsers.pyx:1960, in pandas._libs.parsers.raise_parser_error()
ParserError: Error tokenizing data. C error: Expected 10 fields in line 7, saw 11
Demo#
Now what!?
Now we google the error message…
And according to this stack overflow page: we should try:
pd.read_csv('data/chord-fingers1.csv', sep=';')
So let’s give it a shot:
chord1 = pd.read_csv("data/chord-fingers1.csv", sep=";")
chord1.head()
| CHORD_ROOT | CHORD_TYPE | CHORD_STRUCTURE | FINGER_POSITIONS | NOTE_NAMES | |
|---|---|---|---|---|---|
| 0 | A# | 13 | 1;3;5;b7;9;11;13 | x,1,0,2,3,4 | A#,C##,G#,B#,F## |
| 1 | A# | 13 | 1;3;5;b7;9;11;13 | 4,x,3,2,1,1 | A#,G#,B#,C##,F## |
| 2 | A# | 13 | 1;3;5;b7;9;11;13 | 1,x,1,2,3,4 | A#,G#,C##,F##,B# |
| 3 | A# | 7(#9) | 1;3;5;b7;#9 | x,1,0,2,4,3 | A#,C##,G#,B##,E# |
| 4 | A# | 7(#9) | 1;3;5;b7;#9 | 2,1,3,3,3,x | A#,C##,G#,B##,E# |
# Let's load in the second part of the dataset in the same way:
chord2 = pd.read_csv("data/chord-fingers2.csv", sep=";")
chord2.head()
| CHORD_ROOT | CHORD_TYPE | CHORD_STRUCTURE | FINGER_POSITIONS | NOTE_NAMES | |
|---|---|---|---|---|---|
| 0 | Ab | 6 | 1;3;5;6 | x,4,2,3,1,x | Ab,C,F,Ab |
| 1 | Ab | 6 | 1;3;5;6 | x,x,3,2,4,1 | Ab,C,F,Ab |
| 2 | Ab | 6 | 1;3;5;6 | 2,x,1,4,x,x | Ab,F,C |
| 3 | Ab | 6 | 1;3;5;6 | 1,x,x,3,4,x | Ab,C,F |
| 4 | Ab | 6 | 1;3;5;6 | x,x,1,3,1,4 | Ab,Eb,F,C |
len(chord1)
598
len(chord2)
2034
len(chord1) + len(chord2)
2632
Combining DataFrames together#
We saw that our dataset came in two parts (chord1 and chord2).
A common task in data analysis is to merge or combine datasets together. There are several combinations we can do.
Let’s look at just a basic one:
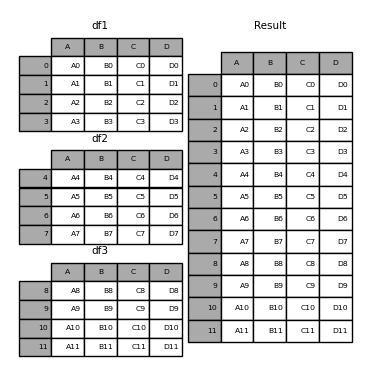
Using .concat()#
Documentation on the .concat() function
# chord1['New Column'] ='Firas'
chord1
| CHORD_ROOT | CHORD_TYPE | CHORD_STRUCTURE | FINGER_POSITIONS | NOTE_NAMES | |
|---|---|---|---|---|---|
| 0 | A# | 13 | 1;3;5;b7;9;11;13 | x,1,0,2,3,4 | A#,C##,G#,B#,F## |
| 1 | A# | 13 | 1;3;5;b7;9;11;13 | 4,x,3,2,1,1 | A#,G#,B#,C##,F## |
| 2 | A# | 13 | 1;3;5;b7;9;11;13 | 1,x,1,2,3,4 | A#,G#,C##,F##,B# |
| 3 | A# | 7(#9) | 1;3;5;b7;#9 | x,1,0,2,4,3 | A#,C##,G#,B##,E# |
| 4 | A# | 7(#9) | 1;3;5;b7;#9 | 2,1,3,3,3,x | A#,C##,G#,B##,E# |
| ... | ... | ... | ... | ... | ... |
| 593 | Ab | m7 | 1;b3;5;b7 | 1,3,1,1,1,x | Ab,Eb,Gb,Cb,Eb |
| 594 | Ab | dim | 1;b3;b5 | x,x,4,3,1,2 | Ab,Cb,Ebb,Ab |
| 595 | Ab | dim | 1;b3;b5 | x,1,2,4,3,x | Ab,Ebb,Ab,Cb |
| 596 | Ab | 6 | 1;3;5;6 | x,x,1,1,1,1 | Eb,Ab,C,F |
| 597 | Ab | 6 | 1;3;5;6 | 1,x,3,2,4,1 | Ab,Ab,C,F,Ab |
598 rows × 5 columns
pd.concat([chord1, chord2])
| CHORD_ROOT | CHORD_TYPE | CHORD_STRUCTURE | FINGER_POSITIONS | NOTE_NAMES | |
|---|---|---|---|---|---|
| 0 | A# | 13 | 1;3;5;b7;9;11;13 | x,1,0,2,3,4 | A#,C##,G#,B#,F## |
| 1 | A# | 13 | 1;3;5;b7;9;11;13 | 4,x,3,2,1,1 | A#,G#,B#,C##,F## |
| 2 | A# | 13 | 1;3;5;b7;9;11;13 | 1,x,1,2,3,4 | A#,G#,C##,F##,B# |
| 3 | A# | 7(#9) | 1;3;5;b7;#9 | x,1,0,2,4,3 | A#,C##,G#,B##,E# |
| 4 | A# | 7(#9) | 1;3;5;b7;#9 | 2,1,3,3,3,x | A#,C##,G#,B##,E# |
| ... | ... | ... | ... | ... | ... |
| 2029 | G | sus4 | 1;4;5 | x,1,2,3,4,1 | G,D,G,C,D |
| 2030 | G | sus4 | 1;4;5 | x,x,3,4,1,1 | G,C,D,G |
| 2031 | G | 6/9 | 1;3;5;6;9 | 2,1,1,1,3,4 | G,B,E,A,D,G |
| 2032 | G | 6/9 | 1;3;5;6;9 | x,x,2,1,3,4 | G,B,E,A |
| 2033 | G | 6/9 | 1;3;5;6;9 | x,2,1,1,3,4 | G,B,E,A,D |
2632 rows × 5 columns
# You NEED to save the output of all pandas function, do NOT use the "inplace" argument, it will be deprecated soon
chords = pd.concat([chord1, chord2])
chords
| CHORD_ROOT | CHORD_TYPE | CHORD_STRUCTURE | FINGER_POSITIONS | NOTE_NAMES | |
|---|---|---|---|---|---|
| 0 | A# | 13 | 1;3;5;b7;9;11;13 | x,1,0,2,3,4 | A#,C##,G#,B#,F## |
| 1 | A# | 13 | 1;3;5;b7;9;11;13 | 4,x,3,2,1,1 | A#,G#,B#,C##,F## |
| 2 | A# | 13 | 1;3;5;b7;9;11;13 | 1,x,1,2,3,4 | A#,G#,C##,F##,B# |
| 3 | A# | 7(#9) | 1;3;5;b7;#9 | x,1,0,2,4,3 | A#,C##,G#,B##,E# |
| 4 | A# | 7(#9) | 1;3;5;b7;#9 | 2,1,3,3,3,x | A#,C##,G#,B##,E# |
| ... | ... | ... | ... | ... | ... |
| 2029 | G | sus4 | 1;4;5 | x,1,2,3,4,1 | G,D,G,C,D |
| 2030 | G | sus4 | 1;4;5 | x,x,3,4,1,1 | G,C,D,G |
| 2031 | G | 6/9 | 1;3;5;6;9 | 2,1,1,1,3,4 | G,B,E,A,D,G |
| 2032 | G | 6/9 | 1;3;5;6;9 | x,x,2,1,3,4 | G,B,E,A |
| 2033 | G | 6/9 | 1;3;5;6;9 | x,2,1,1,3,4 | G,B,E,A,D |
2632 rows × 5 columns
Using .rename()#
Documentation on the .rename() function:
# Capitals annoy me!
list(chords.columns)
['CHORD_ROOT',
'CHORD_TYPE',
'CHORD_STRUCTURE',
'FINGER_POSITIONS',
'NOTE_NAMES']
{k:k.lower() for k in list(chords.columns)}
{'CHORD_ROOT': 'chord_root',
'CHORD_TYPE': 'chord_type',
'CHORD_STRUCTURE': 'chord_structure',
'FINGER_POSITIONS': 'finger_positions',
'NOTE_NAMES': 'note_names'}
chords = chords.rename(columns = {k:k.lower() for k in list(chords.columns)})
chords.head()
| chord_root | chord_type | chord_structure | finger_positions | note_names | |
|---|---|---|---|---|---|
| 0 | A# | 13 | 1;3;5;b7;9;11;13 | x,1,0,2,3,4 | A#,C##,G#,B#,F## |
| 1 | A# | 13 | 1;3;5;b7;9;11;13 | 4,x,3,2,1,1 | A#,G#,B#,C##,F## |
| 2 | A# | 13 | 1;3;5;b7;9;11;13 | 1,x,1,2,3,4 | A#,G#,C##,F##,B# |
| 3 | A# | 7(#9) | 1;3;5;b7;#9 | x,1,0,2,4,3 | A#,C##,G#,B##,E# |
| 4 | A# | 7(#9) | 1;3;5;b7;#9 | 2,1,3,3,3,x | A#,C##,G#,B##,E# |
Using .replace()#
Documentation on the .replace() function:
chords_cleaned = chords.replace("A#", "A-sharp")
chords_cleaned
| chord_root | chord_type | chord_structure | finger_positions | note_names | |
|---|---|---|---|---|---|
| 0 | A-sharp | 13 | 1;3;5;b7;9;11;13 | x,1,0,2,3,4 | A#,C##,G#,B#,F## |
| 1 | A-sharp | 13 | 1;3;5;b7;9;11;13 | 4,x,3,2,1,1 | A#,G#,B#,C##,F## |
| 2 | A-sharp | 13 | 1;3;5;b7;9;11;13 | 1,x,1,2,3,4 | A#,G#,C##,F##,B# |
| 3 | A-sharp | 7(#9) | 1;3;5;b7;#9 | x,1,0,2,4,3 | A#,C##,G#,B##,E# |
| 4 | A-sharp | 7(#9) | 1;3;5;b7;#9 | 2,1,3,3,3,x | A#,C##,G#,B##,E# |
| ... | ... | ... | ... | ... | ... |
| 2029 | G | sus4 | 1;4;5 | x,1,2,3,4,1 | G,D,G,C,D |
| 2030 | G | sus4 | 1;4;5 | x,x,3,4,1,1 | G,C,D,G |
| 2031 | G | 6/9 | 1;3;5;6;9 | 2,1,1,1,3,4 | G,B,E,A,D,G |
| 2032 | G | 6/9 | 1;3;5;6;9 | x,x,2,1,3,4 | G,B,E,A |
| 2033 | G | 6/9 | 1;3;5;6;9 | x,2,1,1,3,4 | G,B,E,A,D |
2632 rows × 5 columns
Using .drop()#
Documentation on the .drop() function:
chords_cleaned
| chord_root | chord_type | chord_structure | |
|---|---|---|---|
| 0 | A-sharp | 13 | 1;3;5;b7;9;11;13 |
| 1 | A-sharp | 13 | 1;3;5;b7;9;11;13 |
| 2 | A-sharp | 13 | 1;3;5;b7;9;11;13 |
| 3 | A-sharp | 7(#9) | 1;3;5;b7;#9 |
| 4 | A-sharp | 7(#9) | 1;3;5;b7;#9 |
| ... | ... | ... | ... |
| 2029 | G | sus4 | 1;4;5 |
| 2030 | G | sus4 | 1;4;5 |
| 2031 | G | 6/9 | 1;3;5;6;9 |
| 2032 | G | 6/9 | 1;3;5;6;9 |
| 2033 | G | 6/9 | 1;3;5;6;9 |
2632 rows × 3 columns
chords_cleaned = chords_cleaned.drop(["finger_positions", "note_names"], axis="columns")
chords_cleaned
| chord_root | chord_type | chord_structure | |
|---|---|---|---|
| 0 | A-sharp | 13 | 1;3;5;b7;9;11;13 |
| 1 | A-sharp | 13 | 1;3;5;b7;9;11;13 |
| 2 | A-sharp | 13 | 1;3;5;b7;9;11;13 |
| 3 | A-sharp | 7(#9) | 1;3;5;b7;#9 |
| 4 | A-sharp | 7(#9) | 1;3;5;b7;#9 |
| ... | ... | ... | ... |
| 2029 | G | sus4 | 1;4;5 |
| 2030 | G | sus4 | 1;4;5 |
| 2031 | G | 6/9 | 1;3;5;6;9 |
| 2032 | G | 6/9 | 1;3;5;6;9 |
| 2033 | G | 6/9 | 1;3;5;6;9 |
2632 rows × 3 columns
sorted(list(chords_cleaned.columns))
chords = chords[sorted(list(chords.columns))]
chords
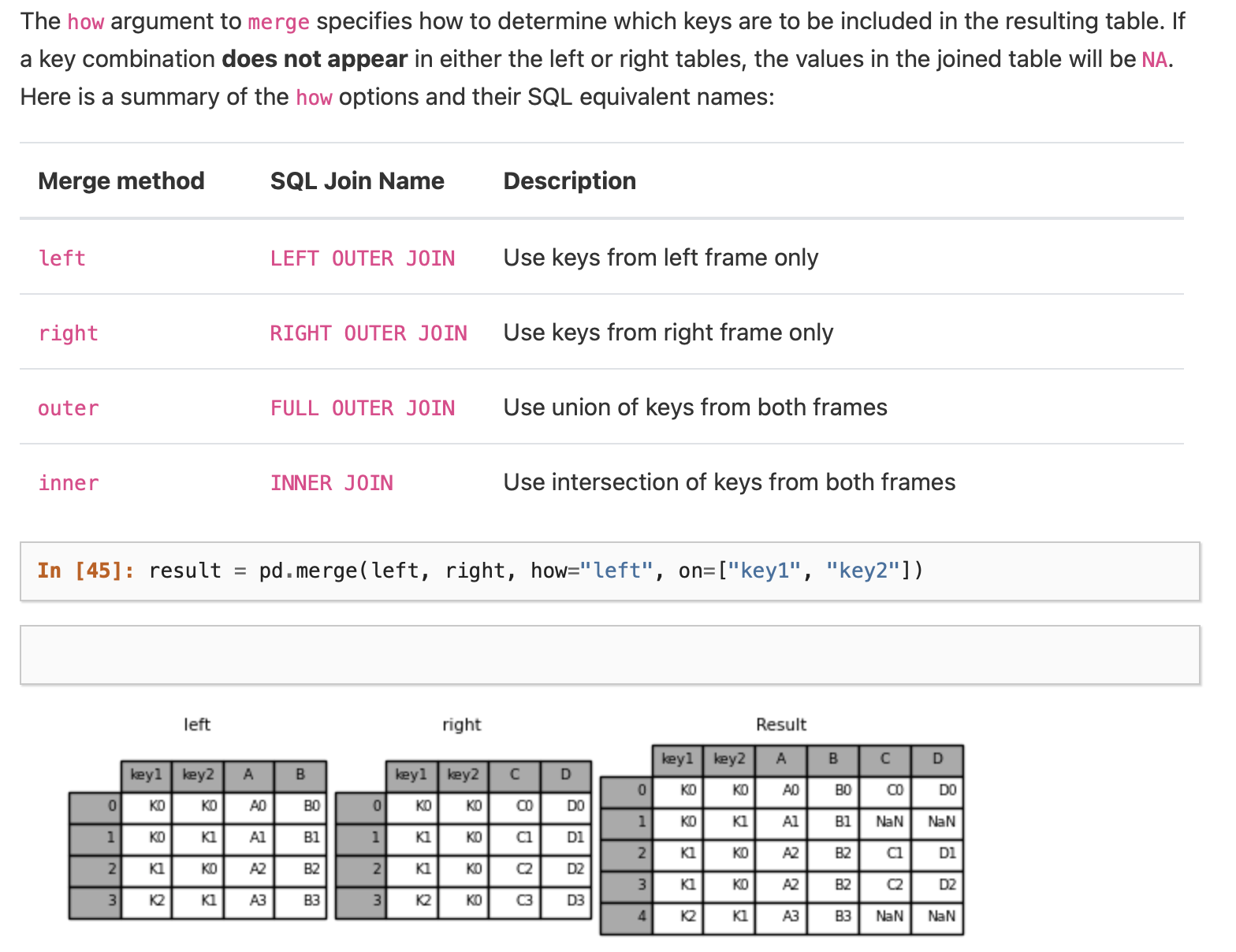
Using .merge()#
User Guide on Merging Dataframes on the .merge() function
Visualizing Data using seaborn and pandas#
This is a preview of content coming later!
# You may need to install seaborn:
# Remember the command to install a package `conda install -c conda-forge seaborn`
import seaborn as sns
sns.countplot(y="Chord", data=chords)
sns.despine()
Additional Notes on Handling Missing Data#
See additional section titled “Wrangling Notes”.
Attribution#

This notebook contains an excerpt from the Python Data Science Handbook by Jake VanderPlas; the content is available on GitHub.
The text is released under the CC-BY-NC-ND license, and code is released under the MIT license. If you find this content useful, please consider supporting the work by buying the book!