Note about Labs 5 and 6¶
Due to a scheduling mixup (my fault), I need to combine Labs 5 and 6 together. Do not worry, it is not “twice” the amount of work - the lab is almost the same length (maybe a little longer) but it is about two disparate topics: advanced git and data visualizations.
Lab 5¶
After many years of searching, I have found the PERFECT tutorial to help you get more familiar with git commands, particularly branching, and merging - things you will start encountering when you start collaboratively working on the projects. Rather than make this a milestone task though, I will be including it as part of Lab 5. It’s included here so you know that you should do this part of the lab before proceeding to Task 3 onwards. You are responsible for completing the following modules (at minimum):
“Main: Introduction Sequence” <- This should mostly be review.
Exercise 1
Exercise 2
Exercise 3
Exercise 4
“Remote: Push & Pull – Git Remotes” <- This is new stuff and you should spend time working through the tutorial.
Exercise 1
Exercise 2
Exercise 3
Exercise 4
Exercise 5
Exercise 6
Exercise 7
Exercise 8
Please include screenshots for your Git Tutorial here:

Lab 6¶
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
A: Setting the Aesthetics for the plots (2 marks)¶
A1: Set the Seaborn figure theme and scale up the text in the figures (2 marks)¶
There are five preset Seaborn themes: darkgrid, whitegrid, dark, white, and ticks.
They are each suited to different applications and personal preferences.
You can see what they look like here.
Hint: You will need to use the font_scale property of the set_theme() function in Seaborn.
# Your Solution Here
sns.set_theme(style="white",
font_scale=1.3)
B: Exploratory Data Analysis (40 marks)¶
B1. Describe your dataset (2 marks)¶
Consider the following questions to guide you in your exploration:
Who: Which company/agency/organization provided this data?
What: What is in your data?
When: When was your data collected (for example, for which years)?
Why: What is the purpose of your dataset? Is it for transparency/accountability, public interest, fun, learning, etc…
How: How was your data collected? Was it a human collecting the data? Historical records digitized? Server logs?
Hint: The pokemon dataset is from this Kaggle page.
Hint: You probably will not need more than 250 words to describe your dataset. All the questions above do not need to be answered, it’s more to guide your exploration and think a little bit about the context of your data. It is also possible you will not know the answers to some of the questions above, that is FINE - data scientists are often faced with the challenge of analyzing data from unknown sources. Do your best, acknowledge the limitations of your data as well as your understanding of it. Also, make it clear what you’re speculating about. For example, “I speculate that the {…column_name…} column must be related to {….} because {….}.”
B2. Load the dataset from a file, or URL (1 mark)¶
This needs to be a pandas dataframe. Remember that others may be running your jupyter notebook so it’s important that the data is accessible to them. If your dataset isn’t accessible as a URL, make sure to commit it into your repo. If your dataset is too large to commit (>100 MB), and it’s not possible to get a URL to it, you should contact your instructor for advice.
You can use this URL to load the data: https://github.com/firasm/bits/raw/master/pokemon.csv
# Your solution here
df = pd.read_csv('https://github.com/firasm/bits/raw/master/pokemon.csv')
B3. Explore your dataset (3 marks)¶
Which of your columns are interesting/relevant? Remember to take some notes on your observations, you’ll need them for the next EDA step (initial thoughts).
B3.1: You should start with df.describe().T (2 marks)¶
See [linked documentation]((https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.describe.html) for the use of include/exclude to look at numerical and categorical data.
# Your solution to output `df.describe.T` for numerical columns:
df.describe(exclude=np.object).T
| count | unique | top | freq | mean | std | min | 25% | 50% | 75% | max | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| # | 800 | NaN | NaN | NaN | 362.814 | 208.344 | 1 | 184.75 | 364.5 | 539.25 | 721 |
| Total | 800 | NaN | NaN | NaN | 435.103 | 119.963 | 180 | 330 | 450 | 515 | 780 |
| HP | 800 | NaN | NaN | NaN | 69.2588 | 25.5347 | 1 | 50 | 65 | 80 | 255 |
| Attack | 800 | NaN | NaN | NaN | 79.0012 | 32.4574 | 5 | 55 | 75 | 100 | 190 |
| Defense | 800 | NaN | NaN | NaN | 73.8425 | 31.1835 | 5 | 50 | 70 | 90 | 230 |
| Sp. Atk | 800 | NaN | NaN | NaN | 72.82 | 32.7223 | 10 | 49.75 | 65 | 95 | 194 |
| Sp. Def | 800 | NaN | NaN | NaN | 71.9025 | 27.8289 | 20 | 50 | 70 | 90 | 230 |
| Speed | 800 | NaN | NaN | NaN | 68.2775 | 29.0605 | 5 | 45 | 65 | 90 | 180 |
| Generation | 800 | NaN | NaN | NaN | 3.32375 | 1.66129 | 1 | 2 | 3 | 5 | 6 |
| Legendary | 800 | 2 | False | 735 | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
# Your solution to output `df.describe.T` for categorical columns:
df.describe(exclude=np.number).T
| count | unique | top | freq | |
|---|---|---|---|---|
| Name | 800 | 800 | Chikorita | 1 |
| Type 1 | 800 | 18 | Water | 112 |
| Type 2 | 414 | 18 | Flying | 97 |
| Legendary | 800 | 2 | False | 735 |
B3.2 Let’s try pandas_profiling now. (1 mark)¶
Hint: To install the pandas_profiling package, you’ll need to use conda:
conda install -c conda-forge pandas-profiling
import pandas_profiling
# Your solution for `pandas_profiling`
# pandas_profiling.ProfileReport(df)
B4. Initial Thoughts (2 marks)¶
B4.1. Use this section to record your observations. (2 marks)¶
Does anything jump out at you as surprising or particularly interesting?
Where do you think you’ll go with exploring this dataset? Feel free to take notes in this section and use it as a scratch pad.
Any content in this area will only be marked for effort and completeness.
# Your observations here:¶
Obs 1
Obs 2
…
B5. Wrangling (5 marks)¶
The next step is to wrangle your data based on your initial explorations. Normally, by this point, you have some idea of what your research question will be, and that will help you narrow and focus your dataset.
In this lab, we will guide you through some wrangling tasks with this dataset.
B5.1. Drop the ‘Generation’, ‘Sp. Atk’, ‘Sp. Def’, ‘Total’, and the ‘#’ columns (1 mark)¶
# Your solution here
df = df.drop(['Sp. Atk', 'Sp. Def', 'Total', '#'], axis=1)
B5.2. Drop any NaN values in HP, Attack, Defense, Speed (1 mark)¶
# Your solution here
df = df.dropna(subset=['HP','Attack','Defense','Speed'])
B5.3. Reset the index to get a new index without missing values (1 mark)¶
# Your solution here
df = df.reset_index()
B5.4. A new column was added called index; remove it. (1 mark)¶
# Your solution here
df = df.drop(['index'], axis=1)
B5.5. Calculate a new column called “Weighted Score” that computes an aggregate score comprising:¶
20% ‘HP’
40% ‘Attack’
30% ‘Defense’
10% ‘Speed’
(1 mark)
# Your solution here
df['Weighted_Score'] = df['HP']*0.2 +\
df['Attack']*0.4 +\
df['Defense']*0.3 +\
df['Speed']*0.1
B6. Research questions (2 marks)¶
B6.1 Come up with at least two research questions about your dataset that will require data visualizations to help answer. (2 marks)¶
Recall that for this purpose, you should only aim for “Descriptive” or “Exploratory” research questions.
Hint1: You are welcome to calculate any columns that you think might be useful to answer the question (or re-add dropped columns like ‘Generation’, ‘Sp. Atk’, ‘Sp. Def’.*
Hint2: Try not to overthink this; this is a toy dataset about Pokémon, you’re not going to solve climate change or cure world hunger. Focus your research questions on the various Pokémon attributes, and the types.
# Your solution here:¶
1. Sample Research Question: Which Pokemon Types are the best, as determined by the Weighted Score?
2. Your RQ 1:
3. Your RQ 2:
B7. Data Analysis and Visualizations¶
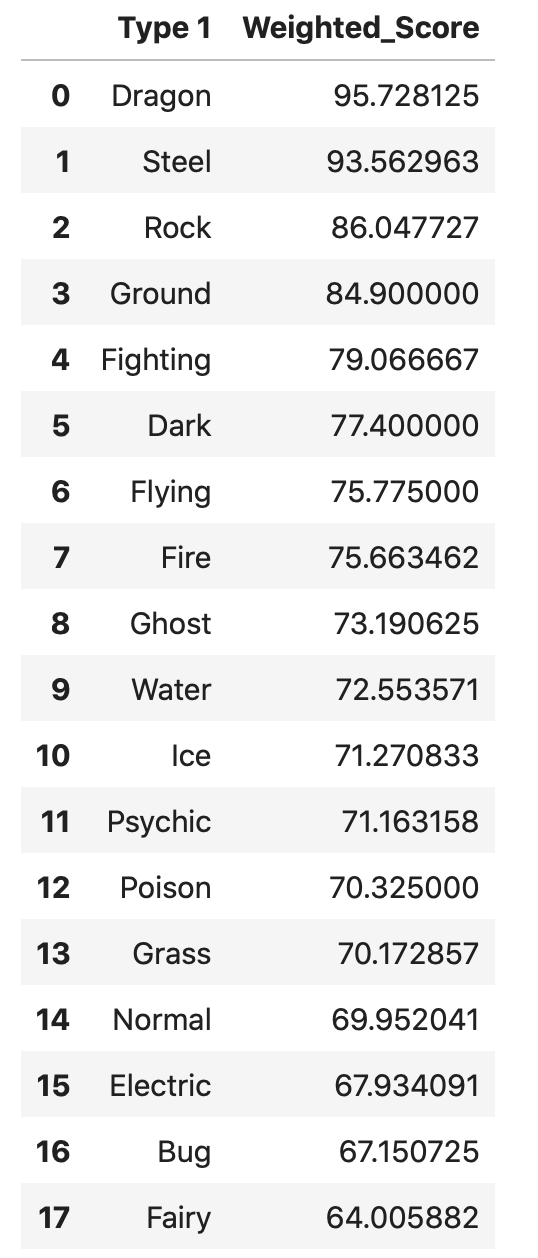
B7.1. Sample Research Question: Which Pokemon Types are the best, as determined by the Weighted Score? (3 marks)¶
To answer this question, we will first need to do wrangle the data to return the mean Weighted_Score, split by the Pokemon Type 1.
Here is the goal of this analysis:
# Your Solution here
order_df = (df
.groupby('Type 1')['Weighted_Score']
.mean()
.sort_values(ascending=False)
.to_frame()
.reset_index()
)
order_df
| Type 1 | Weighted_Score | |
|---|---|---|
| 0 | Dragon | 95.728125 |
| 1 | Steel | 93.562963 |
| 2 | Rock | 86.047727 |
| 3 | Ground | 84.900000 |
| 4 | Fighting | 79.066667 |
| 5 | Dark | 77.400000 |
| 6 | Flying | 75.775000 |
| 7 | Fire | 75.663462 |
| 8 | Ghost | 73.190625 |
| 9 | Water | 72.553571 |
| 10 | Ice | 71.270833 |
| 11 | Psychic | 71.163158 |
| 12 | Poison | 70.325000 |
| 13 | Grass | 70.172857 |
| 14 | Normal | 69.952041 |
| 15 | Electric | 67.934091 |
| 16 | Bug | 67.150725 |
| 17 | Fairy | 64.005882 |
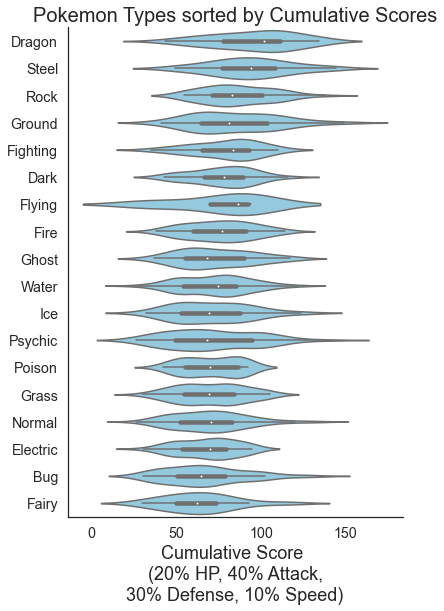
B7.2. Create a violin plot to show the distribution of Weighted_Scores split by all the Pokémon types. (2 marks)¶
Here is the goal:
# Your Solution here
fig, ax = plt.subplots(figsize=(6, 9))
sns.violinplot(data=df,
y = 'Type 1',
x = 'Weighted_Score',
scale='width',
order = order_df['Type 1'].tolist(),
#palette = "Blues_r",
color='skyblue'
)
plt.ylabel('')
plt.xlabel('Cumulative Score \n (20% HP, 40% Attack, \n30% Defense, 10% Speed)',fontsize=18)
plt.title('Pokemon Types sorted by Cumulative Scores\n',fontsize=20)
sns.despine()
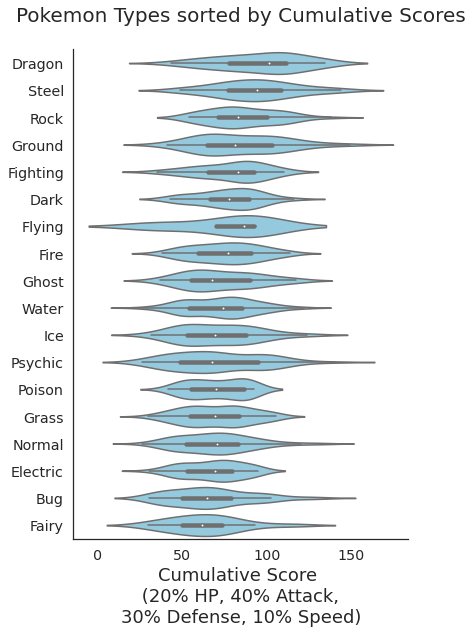
B7.3. Create a Box Plot and overlay a strip plot (2 marks)¶
Here is the goal:

# Your Solution here
plt.subplots(figsize=(6, 9))
sns.boxplot(data=df,
x='Weighted_Score',
y='Type 1',
order = order_df['Type 1'].tolist(),
palette="vlag",
width=0.6)
sns.stripplot(x="Weighted_Score", y="Type 1", data=df,
size=3, color=".2", linewidth=0)
plt.ylabel('')
plt.title('Box plot of Pokémon Weighted_Scores by Type\n',fontsize=20)
plt.xlabel('Cumulative Score \n (20% HP, 40% Attack, \n30% Defense, 10% Speed)',fontsize=18)
sns.despine(left=True)

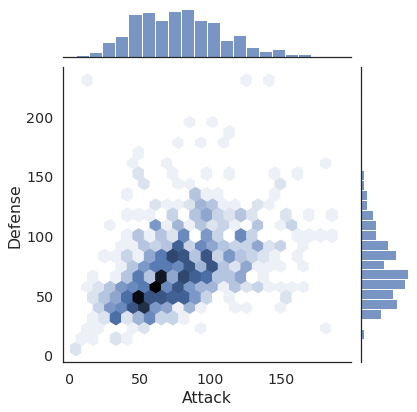
7.4. Create a Hexbin plot with marginal distributions (2 marks)¶
This plot helps you visualize large amounts of data (and its distributions) by using colours to represent the number of points in a hexagonal shape.
Here is the goal:
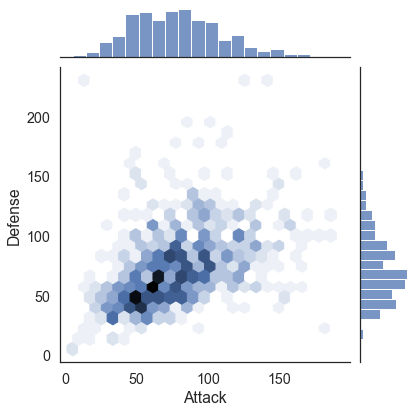
# Your Solution here
sns.jointplot(data=df, x='Attack', y='Defense', kind='hex')
<seaborn.axisgrid.JointGrid at 0x7f50d55bff50>
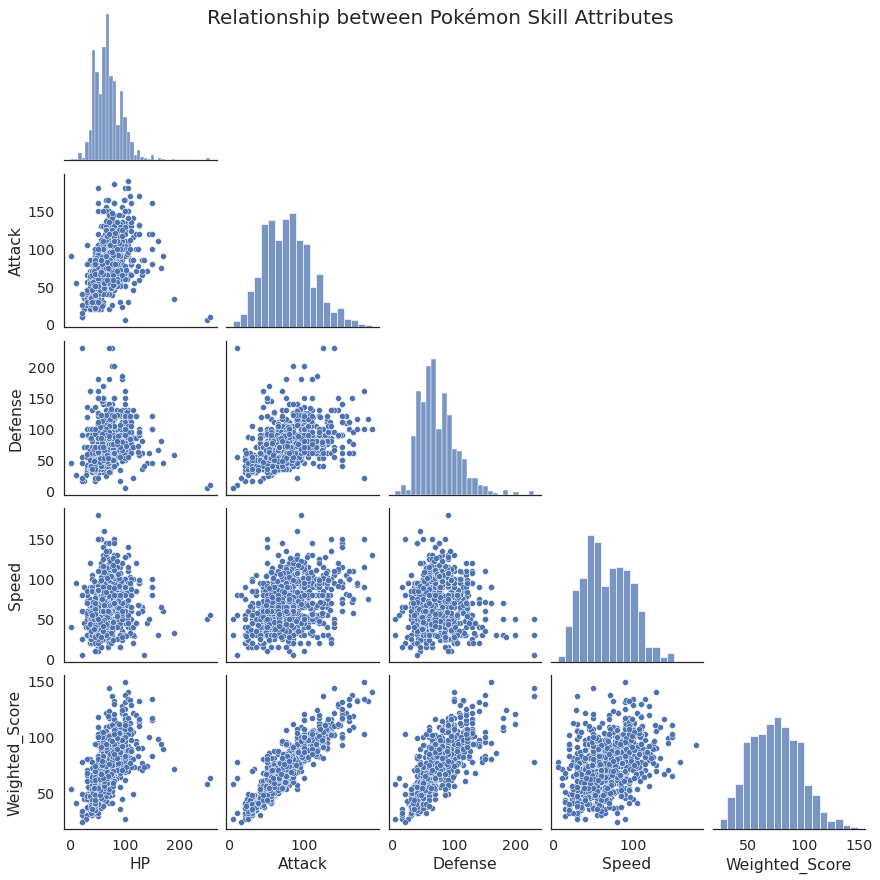
B7.5. Create a PairPlot of the quantiative features of the pokémon dataset (1 mark)¶
Here is the goal:
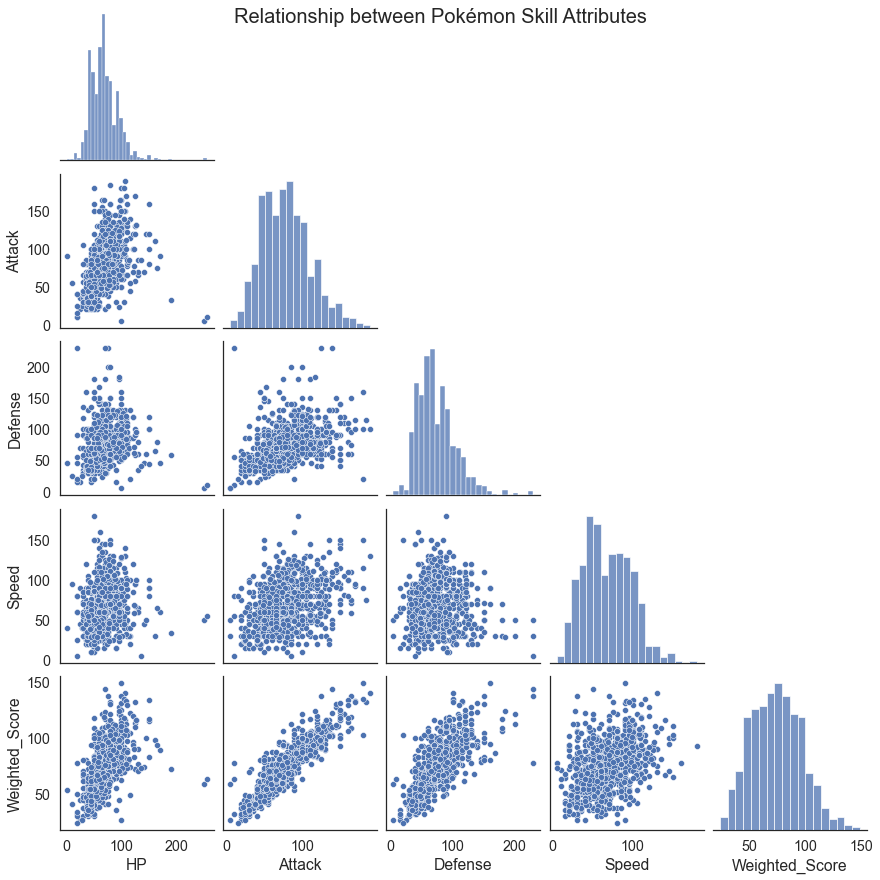
# Your Solution here
g = sns.pairplot(data=df.select_dtypes(include='number').drop('Generation',axis=1),
corner=True)
g.fig.suptitle('Relationship between Pokémon Skill Attributes',fontsize=20)
Text(0.5, 0.98, 'Relationship between Pokémon Skill Attributes')
B7.6. Create a visualization that helps you answer your first research question (2 marks)¶
# Your Solution here
B7.7. Create a visualization that helps you answer your second research question (2 marks)¶
# Your Solution here
B8. Summary and conclusions (3 marks)¶
B8.1. Summarize your findings and describe any conclusions and insight you were able to draw from your visualizations. (3 marks)¶
Sample Research Question: Which Pokemon Types are the best, as determined by the Weighted Score? (3 marks)
Summary of findings, insight, and conclusions
..
Research Question 1: RQ here
Summary of findings, insight, and conclusions
..
Research Question 2: RQ here
Summary of findings, insight, and conclusions
..
C. Method Chaining (8 marks)¶
Method chaining allows you to apply multiple processing steps to your dataframe in a fewer lines of code so it is more readable. You should avoid having too many methods in your chain, as the more you have in a single chain, the harder it is to debug or troubleshoot. I would target about 5 methods in a chain, though this is a flexible suggestion and you should do what makes your analysis the most readable and group your chains based on their purpose (e.g., loading/cleaning, processing, etc…).
Note: See Milestone 2 for a more thorough description of method chaining.
C1. Use Method Chaining on the commands from sections B5.1, B5.2, B5.3, B5.4, B5.5. (4 marks)¶
# Your Solution here
# Generally a good idea to split wrangling, cleaning, and processing into separate "chains" for easier debugging
# This is not a hard and fast rule, just a recommendation
df = (
pd.read_csv('https://github.com/firasm/bits/raw/master/pokemon.csv')
.drop(['Sp. Atk', 'Sp. Def', 'Total', '#'], axis=1)
.dropna(subset=['HP','Attack','Defense','Speed'])
.reset_index()
.drop(['index','Type 2'], axis=1)
.assign(Weighted_Score = df['HP']*0.2 +\
df['Attack']*0.4 +\
df['Defense']*0.3 +\
df['Speed']*0.1)
)
C2. Use Method Chaining to do the tasks below. (4 marks)¶
Remove all Pokémon 6th generation and above.
Remove the Legendary column.
Remove all rows that contain “Forme”, a special form of Pokémon.
Remove all rows that contain “Mega”, another weird special form of Pokémon.
Hint: You will need to use the .loc in combination with the anonymous function lambda.
# Your Solution here
df = (
df
.loc[lambda x: x['Generation']<6]
.loc[lambda x: ~x['Legendary']]
.loc[lambda x: ~x['Name'].str.contains('Forme')]
.loc[lambda x: ~x['Name'].str.contains('Mega')]
)
df
| Name | Type 1 | HP | Attack | Defense | Speed | Generation | Legendary | Weighted_Score | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | Bulbasaur | Grass | 45 | 49 | 49 | 45 | 1 | False | 47.8 |
| 1 | Ivysaur | Grass | 60 | 62 | 63 | 60 | 1 | False | 61.7 |
| 2 | Venusaur | Grass | 80 | 82 | 83 | 80 | 1 | False | 81.7 |
| 4 | Charmander | Fire | 39 | 52 | 43 | 65 | 1 | False | 48.0 |
| 5 | Charmeleon | Fire | 58 | 64 | 58 | 80 | 1 | False | 62.6 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 695 | Zweilous | Dark | 72 | 85 | 70 | 58 | 5 | False | 75.2 |
| 696 | Hydreigon | Dark | 92 | 105 | 90 | 98 | 5 | False | 97.2 |
| 697 | Larvesta | Bug | 55 | 85 | 55 | 60 | 5 | False | 67.5 |
| 698 | Volcarona | Bug | 85 | 60 | 65 | 100 | 5 | False | 70.5 |
| 717 | Genesect | Bug | 71 | 120 | 95 | 99 | 5 | False | 100.6 |
614 rows × 9 columns
D. (OPTIONAL) Advanced Visualizations¶
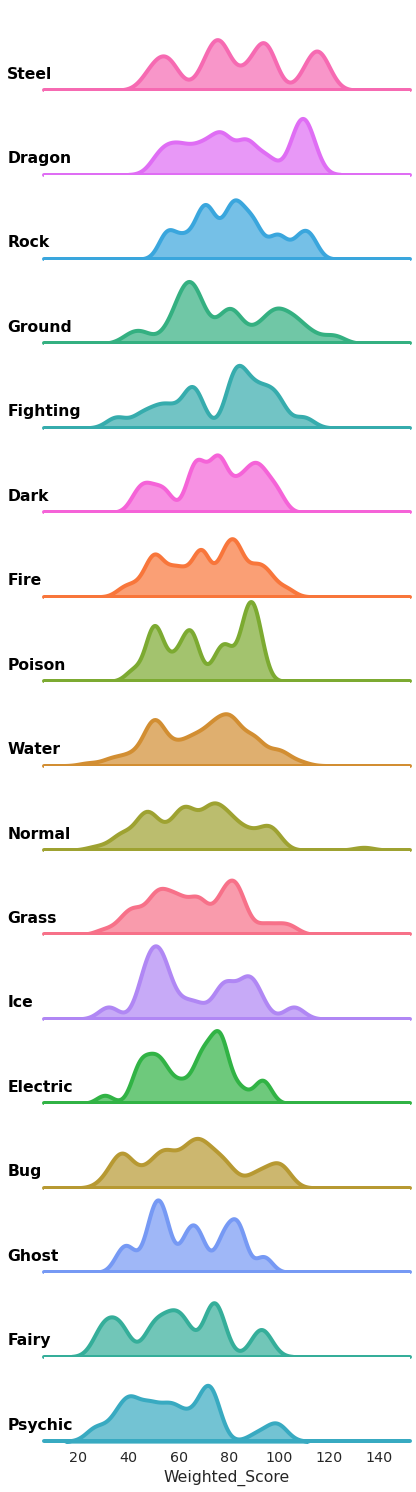
D1. Create a “Ridgeline” plot fron the plots from B7.2 and B7.3 (2 marks).¶
Here is the goal:
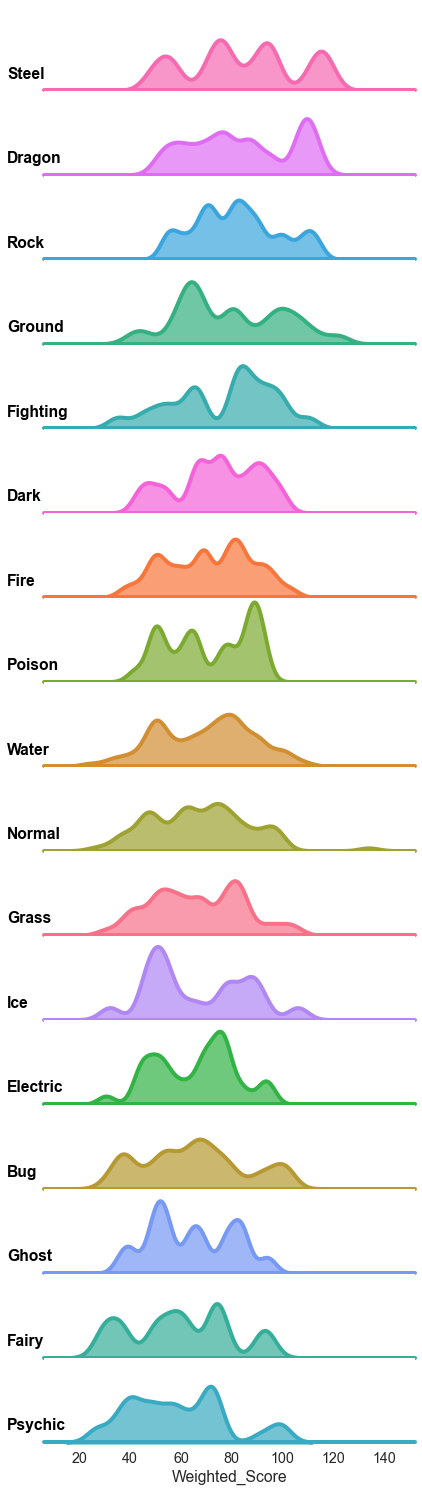
# Your Solution Here
order_df = (df
.groupby('Type 1')['Weighted_Score']
.mean()
.sort_values(ascending=False)
.to_frame()
.reset_index()
)
def label(x, color, label):
ax = plt.gca()
ax.text(-0.1, .2, label, fontweight="bold", color="black",
ha="left", va="center", transform=ax.transAxes)
ridge_plot = sns.FacetGrid(df, row="Type 1",
hue="Type 1", aspect=5,
height=1.25,
row_order = order_df['Type 1'].tolist())
# Draw the densities in a few steps
ridge_plot.map(sns.kdeplot, "Weighted_Score",
clip_on=False, shade=True,
alpha=0.7, lw=4, bw_method=.2)
ridge_plot.map(plt.axhline, y=0, lw=4, clip_on=False)
ridge_plot.map(label, "Weighted_Score")
# Set the subplots to overlap
ridge_plot.fig.subplots_adjust(hspace=0.01)
ridge_plot.set_titles("")
ridge_plot.set(yticks=[])
ridge_plot.despine(bottom=True, left=True)
<seaborn.axisgrid.FacetGrid at 0x7f50cf24edd0>