Lecture 4
Contents
Lecture 4#
Lecture learning goals#
By the end of the lecture you will be able to:
Visualize distributions.
Understand how different distribution plots are made and their pros and cons.
Select an appropriate distribution plot for the situation.
Grasp EDA on a conceptual levels both for numerical and categorical variables.
Create density plots to compare a few distributions.
Create boxplots and violin plot to compare many distributions.
Use repeated plot grids to investigate multiple data frame columns in the same plot.
Visualize correlations and counts of categorical variables.
Readings#
Chapter 7 and 9 of Fundamentals of Data Visualization. No other notes will be posted, since we didn’t include any code of our own and these sections are very close to what I would want to write myself so use this reference and the videos when studying.
Interactive flow chart for which visualization to choose. Not really anything to read, but go there to look around and bookmark it to use as a reference when needed throughout this course and others.
Visualizing distributions fairly#
import pandas as pd
import altair as alt
%load_ext rpy2.ipython
%%R
options(tidyverse.quiet = TRUE)
library(tidyverse)
theme_set(theme_light(base_size = 18))
R[write to console]: Error in (function (filename = "Rplot%03d.png", width = 480, height = 480, :
Graphics API version mismatch
---------------------------------------------------------------------------
RRuntimeError Traceback (most recent call last)
Input In [2], in <cell line: 1>()
----> 1 get_ipython().run_cell_magic('R', '', 'options(tidyverse.quiet = TRUE) \nlibrary(tidyverse)\n\ntheme_set(theme_light(base_size = 18))\n')
File /opt/hostedtoolcache/Python/3.9.13/x64/lib/python3.9/site-packages/IPython/core/interactiveshell.py:2358, in InteractiveShell.run_cell_magic(self, magic_name, line, cell)
2356 with self.builtin_trap:
2357 args = (magic_arg_s, cell)
-> 2358 result = fn(*args, **kwargs)
2359 return result
File /opt/hostedtoolcache/Python/3.9.13/x64/lib/python3.9/site-packages/rpy2/ipython/rmagic.py:765, in RMagics.R(self, line, cell, local_ns)
762 else:
763 cell_display = CELL_DISPLAY_DEFAULT
--> 765 tmpd = self.setup_graphics(args)
767 text_output = ''
768 try:
File /opt/hostedtoolcache/Python/3.9.13/x64/lib/python3.9/site-packages/rpy2/ipython/rmagic.py:461, in RMagics.setup_graphics(self, args)
457 tmpd_fix_slashes = tmpd.replace('\\', '/')
459 if self.device == 'png':
460 # Note: that %% is to pass into R for interpolation there
--> 461 grdevices.png("%s/Rplots%%03d.png" % tmpd_fix_slashes,
462 **argdict)
463 elif self.device == 'svg':
464 self.cairo.CairoSVG("%s/Rplot.svg" % tmpd_fix_slashes,
465 **argdict)
File /opt/hostedtoolcache/Python/3.9.13/x64/lib/python3.9/site-packages/rpy2/robjects/functions.py:203, in SignatureTranslatedFunction.__call__(self, *args, **kwargs)
201 v = kwargs.pop(k)
202 kwargs[r_k] = v
--> 203 return (super(SignatureTranslatedFunction, self)
204 .__call__(*args, **kwargs))
File /opt/hostedtoolcache/Python/3.9.13/x64/lib/python3.9/site-packages/rpy2/robjects/functions.py:126, in Function.__call__(self, *args, **kwargs)
124 else:
125 new_kwargs[k] = cv.py2rpy(v)
--> 126 res = super(Function, self).__call__(*new_args, **new_kwargs)
127 res = cv.rpy2py(res)
128 return res
File /opt/hostedtoolcache/Python/3.9.13/x64/lib/python3.9/site-packages/rpy2/rinterface_lib/conversion.py:45, in _cdata_res_to_rinterface.<locals>._(*args, **kwargs)
44 def _(*args, **kwargs):
---> 45 cdata = function(*args, **kwargs)
46 # TODO: test cdata is of the expected CType
47 return _cdata_to_rinterface(cdata)
File /opt/hostedtoolcache/Python/3.9.13/x64/lib/python3.9/site-packages/rpy2/rinterface.py:813, in SexpClosure.__call__(self, *args, **kwargs)
806 res = rmemory.protect(
807 openrlib.rlib.R_tryEval(
808 call_r,
809 call_context.__sexp__._cdata,
810 error_occured)
811 )
812 if error_occured[0]:
--> 813 raise embedded.RRuntimeError(_rinterface._geterrmessage())
814 return res
RRuntimeError: Error in (function (filename = "Rplot%03d.png", width = 480, height = 480, :
Graphics API version mismatch
Barplots#
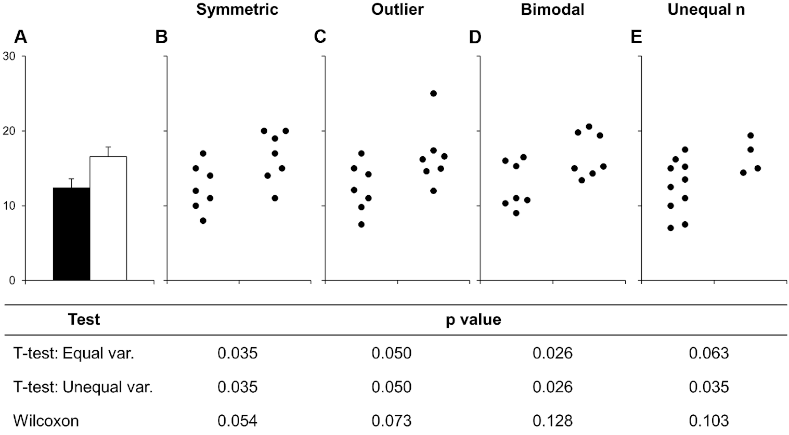
Barplots hide details of distributions by showing only 1 values (or 3 with error bars). Below is an example of this from a scientific article on how to present data accurately. You can see that the bars could hide widely different data distributions, which would lead to different interpretations of the experiment both visually from looking at the points and by examining formal statistical comparisons (the table below the figure, you don’t need to know exactly what these are, just note how different the distributions are).
Boxplots#
Boxplots are better (5-9 values) but can also hide important information. I have included a couple of examples showing how different plot types change when the data changes. This is from Autodesk Research who also made the animation of the datasaurus we saw in lecture 1.
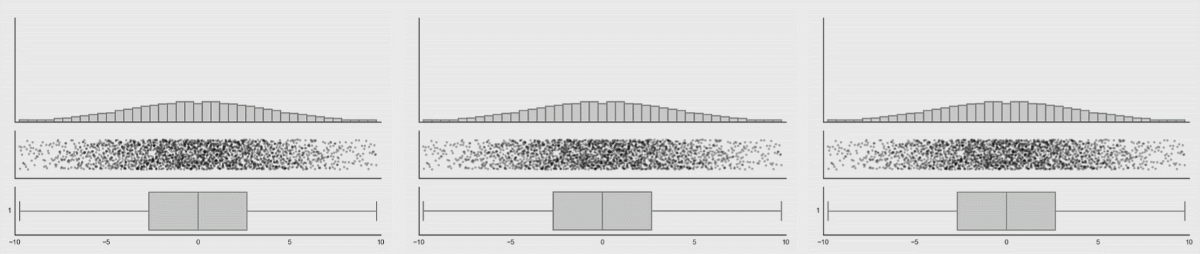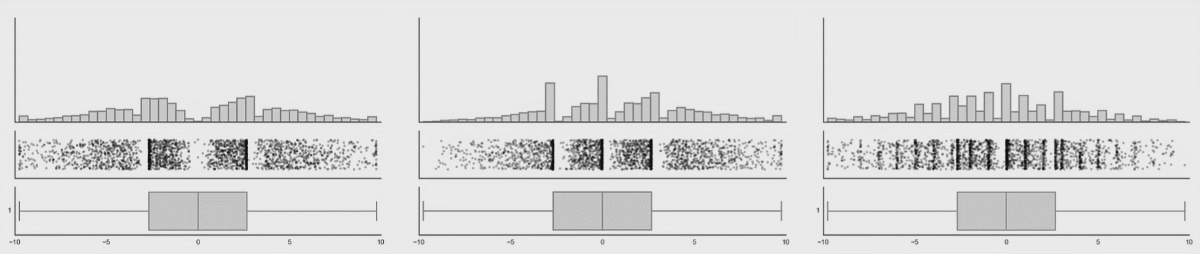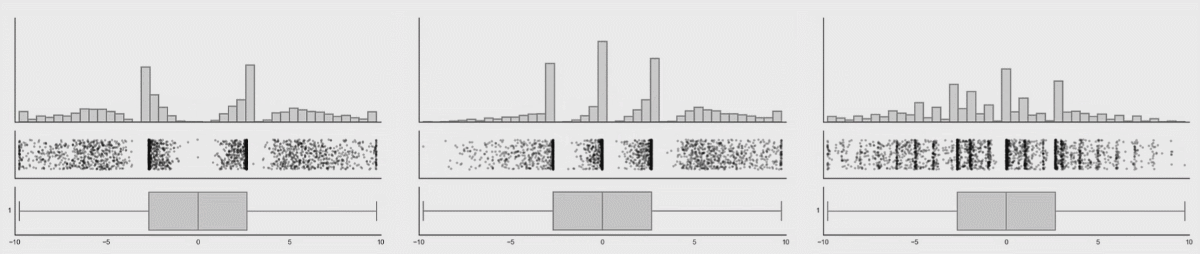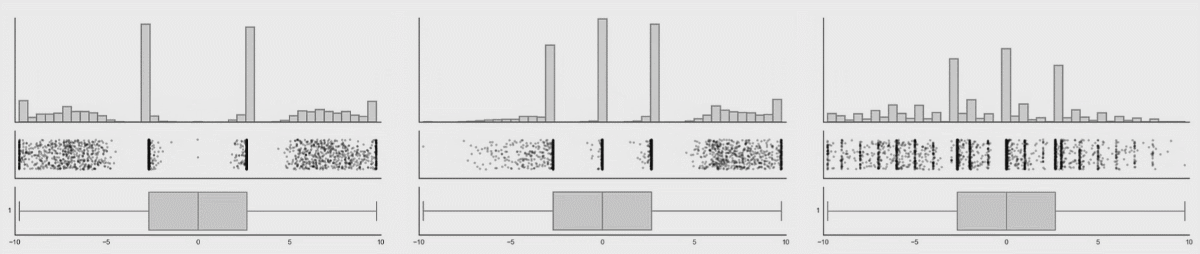
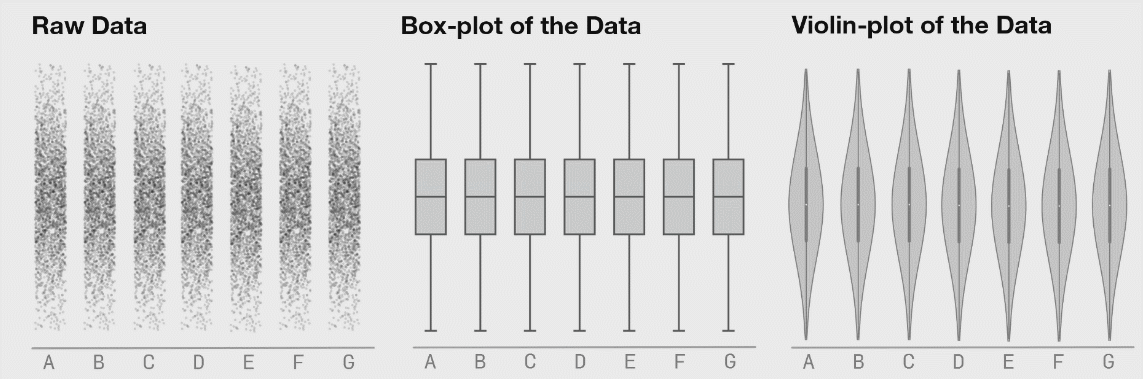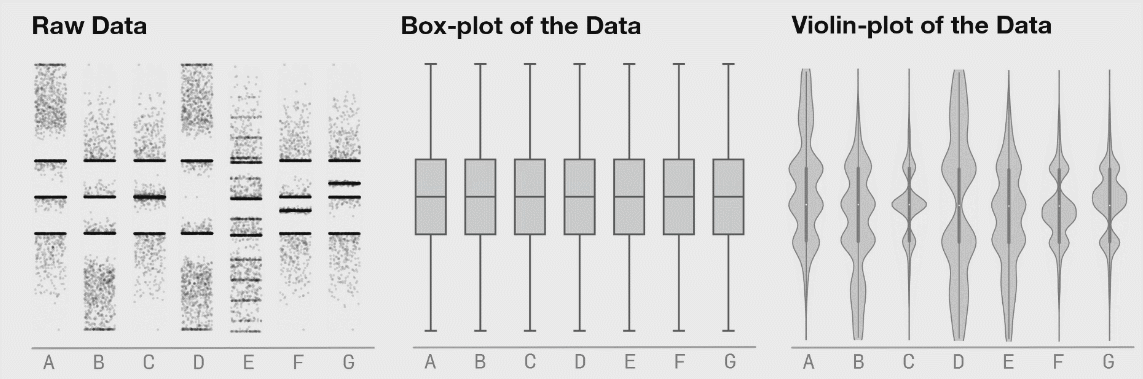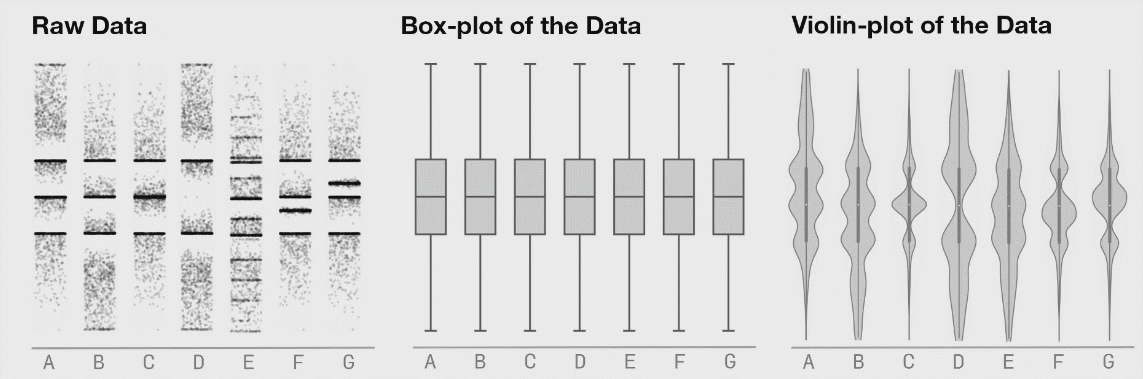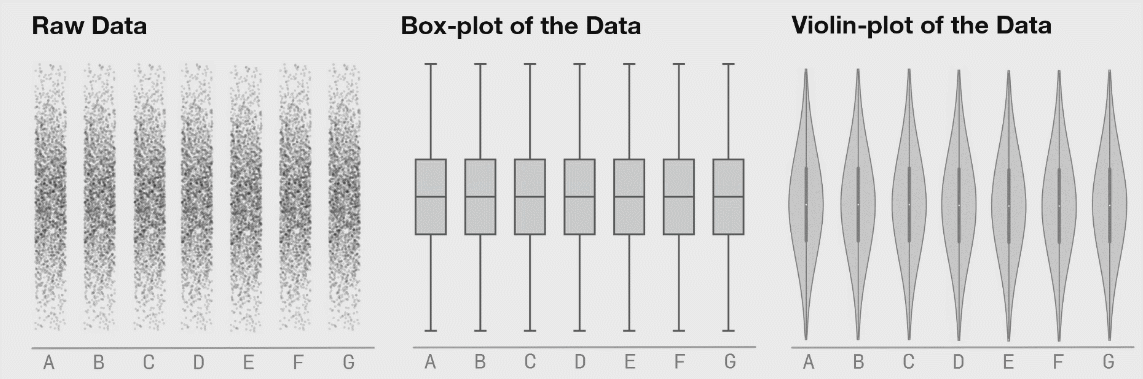
Kernel density estimates#
The animation below shows how a KDE is constructed from first adding individual kernels (curves) centered on each data point and then summing them together (created from this YouTube video):
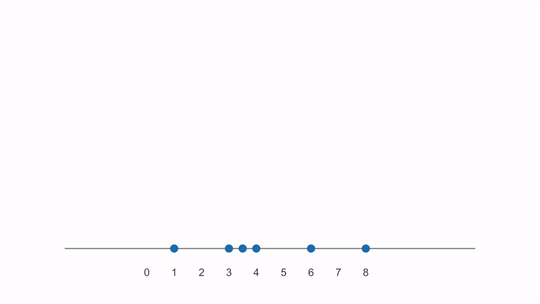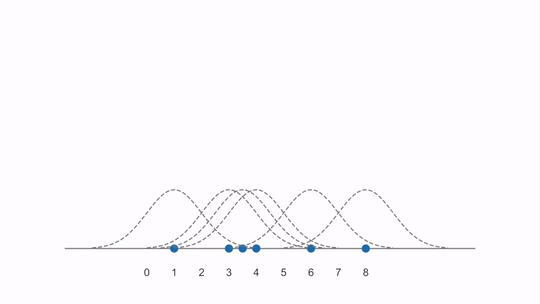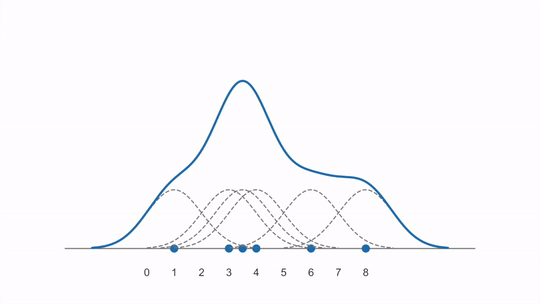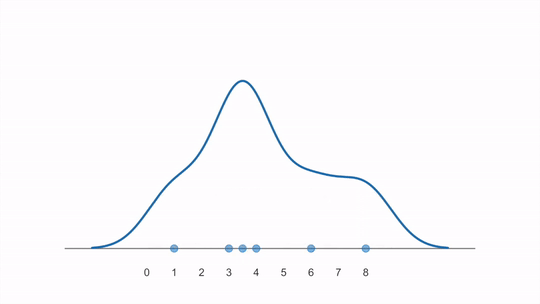
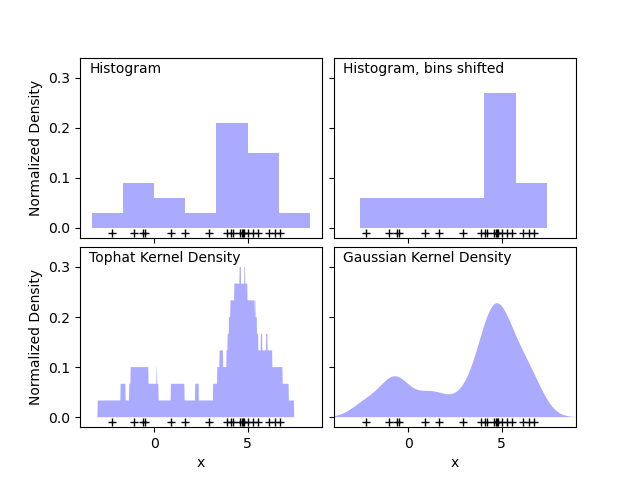
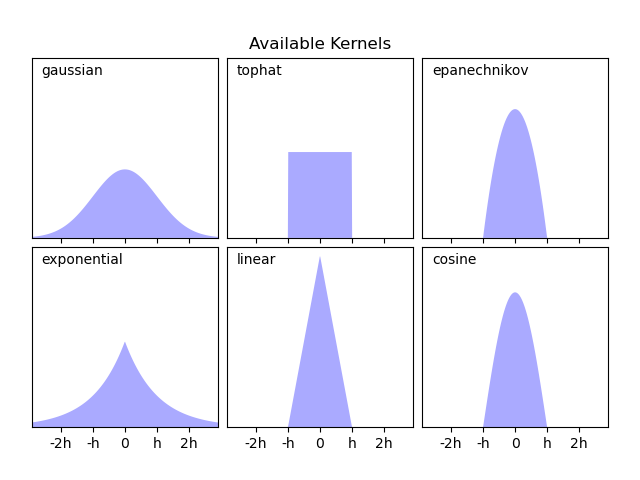
Scikit learn’s documenation on KDEs is great and includes images comparing with histograms and also visualizing the different kernels that could be used.
Distribution plots#
We will use a movie data set similar to the one you will see in lab 2.
movies = pd.read_json('lec-movies.json')
movies
| id | title | runtime | budget | revenue | genres | countries | vote_average | vote_loved_it | vote_count | vote_std | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 12 | Finding Nemo | 100 | 94000000 | 940335536 | [Animation] | [United States of America] | 3.86 | 0.322 | 33887 | 0.87 |
| 1 | 22 | Pirates of the Caribbean: The Curse of the Bla... | 143 | 140000000 | 655011224 | [Fantasy] | [United States of America] | 3.81 | 0.320 | 36337 | 0.91 |
| 2 | 35 | The Simpsons Movie | 87 | 75000000 | 527068851 | [Animation] | [United States of America] | 3.44 | 0.155 | 8621 | 0.92 |
| 3 | 58 | Pirates of the Caribbean: Dead Man's Chest | 151 | 200000000 | 1065659812 | [Fantasy] | [United States of America] | 3.47 | 0.198 | 15079 | 0.98 |
| 4 | 75 | Mars Attacks! | 106 | 70000000 | 101371017 | [Fantasy] | [United States of America] | 2.96 | 0.086 | 19515 | 1.10 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 675 | 374720 | Dunkirk | 107 | 100000000 | 519876949 | [History] | [United Kingdom, United States of America] | 4.11 | 0.465 | 282 | 0.78 |
| 676 | 378236 | The Emoji Movie | 86 | 50000000 | 66913939 | [Animation] | [United States of America] | 0.63 | 0.000 | 19 | 0.23 |
| 677 | 381289 | A Dog's Purpose | 100 | 22000000 | 194647323 | [Fantasy] | [United States of America] | 3.61 | 0.284 | 109 | 1.17 |
| 678 | 382322 | Batman: The Killing Joke | 72 | 3500000 | 3775000 | [Animation] | [United States of America] | 2.94 | 0.057 | 209 | 1.02 |
| 679 | 402298 | Denial | 109 | 10000000 | 4073489 | [History] | [United Kingdom, United States of America] | 3.62 | 0.162 | 68 | 0.82 |
680 rows × 11 columns
Let’s recall how to make a histogram, using the runtime of the movies.
(alt.Chart(movies).mark_bar().encode(
alt.X('runtime', bin=alt.Bin(maxbins=30)),
y='count()'))
What if we want to facet the histogram by country?
Since the 'country' column consists of lists with one or more labels,
we need to unpack these list so that we have one country in each row.
This means that movies that have multiple production countries,
will be duplicated in the dataframe and counted once per country.
In this case,
this is the most sensible thing to do,
but in general it is good to be careful when doing an operation like this
since it could lead to unwanted replicates
(and we would not want to have duplicated rows
if we are not faceting or coloring by that variable).
Unpacking a list is done via the explode method of pandas dataframes
and there is a illustrative example in the documentation to help understand the outcome of this operation:

movies.explode('countries')
| id | title | runtime | budget | revenue | genres | countries | vote_average | vote_loved_it | vote_count | vote_std | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 12 | Finding Nemo | 100 | 94000000 | 940335536 | [Animation] | United States of America | 3.86 | 0.322 | 33887 | 0.87 |
| 1 | 22 | Pirates of the Caribbean: The Curse of the Bla... | 143 | 140000000 | 655011224 | [Fantasy] | United States of America | 3.81 | 0.320 | 36337 | 0.91 |
| 2 | 35 | The Simpsons Movie | 87 | 75000000 | 527068851 | [Animation] | United States of America | 3.44 | 0.155 | 8621 | 0.92 |
| 3 | 58 | Pirates of the Caribbean: Dead Man's Chest | 151 | 200000000 | 1065659812 | [Fantasy] | United States of America | 3.47 | 0.198 | 15079 | 0.98 |
| 4 | 75 | Mars Attacks! | 106 | 70000000 | 101371017 | [Fantasy] | United States of America | 2.96 | 0.086 | 19515 | 1.10 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 676 | 378236 | The Emoji Movie | 86 | 50000000 | 66913939 | [Animation] | United States of America | 0.63 | 0.000 | 19 | 0.23 |
| 677 | 381289 | A Dog's Purpose | 100 | 22000000 | 194647323 | [Fantasy] | United States of America | 3.61 | 0.284 | 109 | 1.17 |
| 678 | 382322 | Batman: The Killing Joke | 72 | 3500000 | 3775000 | [Animation] | United States of America | 2.94 | 0.057 | 209 | 1.02 |
| 679 | 402298 | Denial | 109 | 10000000 | 4073489 | [History] | United Kingdom | 3.62 | 0.162 | 68 | 0.82 |
| 679 | 402298 | Denial | 109 | 10000000 | 4073489 | [History] | United States of America | 3.62 | 0.162 | 68 | 0.82 |
775 rows × 11 columns
boom_countries = movies.explode('countries')
(alt.Chart(boom_countries).mark_bar().encode(
alt.X('runtime', bin=alt.Bin(maxbins=30)),
y='count()')
.facet('countries'))
By default when faceting, the y-axis is the same for all plots so that they are easy to compare, but we could also make it independent for each plot.
(alt.Chart(boom_countries).mark_bar().encode(
alt.X('runtime', bin=alt.Bin(maxbins=30)),
y='count()')
.facet('countries')
.resolve_scale(y='independent'))
If we want to color our faceted plots by the movie genre,
we need to explode also the 'genres' column in the df.
boom_both = boom_countries.explode('genres')
(alt.Chart(boom_both).mark_bar().encode(
alt.X('runtime', bin=alt.Bin(maxbins=30)),
y='count()',
color='genres')
.facet('countries'))
We can get a rough indication of the genre differences from this plot, but as we have mention previously, it is not ideal to be looking at bars with different baselines. Instead we could draw a line for the histograms, since this will not stack on top of each other, but start from the same point of the y-axis.
(alt.Chart(boom_both).mark_line().encode(
alt.X('runtime', bin=alt.Bin(maxbins=30)),
y='count()',
color='genres')
.facet('countries'))
To make the lines appearance more histogram-like, we could change the interpolation method. This refers to how the line behaves between two data points and the default is to draw a diagonal line between data points (euclidean distance/linear interpolation). If we instead use step-wise interpolation (taxicab geometry/manhattan distance), it looks more like a histogram. But please note that I am only showing this for demonstration purposes, this does not quite behave as a histogram and should not be used as such as per this GitHub comment from the Altair author (until this issue is fixed).
(alt.Chart(boom_both).mark_line(interpolate='step').encode(
alt.X('runtime', bin=alt.Bin(maxbins=30)),
y='count()',
color='genres')
.facet('countries'))
We could also prefer a monotone cubic interpolation, which essentially entails rounding the corners while preserving the one-directional (monotone) properties of a linear interpolation (i.e. make sure the line does not wiggle up and down between data points, but proceed gradually from one to the next).
(alt.Chart(boom_both).mark_line(interpolate='monotone').encode(
alt.X('runtime', bin=alt.Bin(maxbins=30)),
y='count()',
color='genres')
.facet('countries'))
While this looks similar to a kernel density estimate (KDE), it is not the same thing and should not be used as such (but it is useful for changing the appearance of line plots in general).
To visualize a KDE, we need to do two things:
Calculate the KDE (adding the individual Gaussian kernels and summing them together)
Plot a line or area mark for the newly calculated KDE values.
In Altair,
these operations are done in two explicit steps,
whereas ggplot has a geom_ that does both in the same step.
(alt.Chart(movies)
.transform_density(
'runtime',
as_=['runtime', 'density']) # Give a name to the KDE values, which we can use when plotting
.mark_area(interpolate='monotone').encode(
x='runtime',
y='density:Q'))
In the above,
we need to use ':Q' to indicate that the density is numeric
since it is not part of the dataframe,
so Altair cannot use the pandas data types to figure out that it is numeric.
If we want to color by a categorical variable,
we need to add an explicit groupby
when calculating the density also,
so that there is one density calculation
per color variable (genres in this case).
boom_genres = movies.explode('genres')
(alt.Chart(boom_genres)
.transform_density(
'runtime',
groupby=['genres'],
as_=['runtime', 'density'])
.mark_area(interpolate='monotone').encode(
x='runtime',
y='density:Q',
color='genres'))
To make the curves smoother, we could use the monotone interpolation mentioned above, but a more proper way of doing this is to increase the resolution over which the KDE is calculated by setting the steps size to a higher number.
(alt.Chart(boom_genres)
.transform_density(
'runtime',
groupby=['genres'],
as_=['runtime', 'density'],
steps=50
)
.mark_area().encode(
x='runtime',
y='density:Q',
color='genres'))
Lastly, we could make the histograms slightly transparent so that it is easier to see the overlap.
(alt.Chart(boom_genres)
.transform_density(
'runtime',
groupby=['genres'],
as_=['runtime', 'density'],
steps=200)
.mark_area(opacity=0.4).encode(
x='runtime',
y='density:Q',
color='genres'))
If we face these, you will notice that they look quite different from the faceted histograms. This is because the density rather than the count is shown by default on the y-axis. Showing the density means that we can see how the area adds up to one, but is not really a useful numbers for us to know.
(alt.Chart(boom_both)
.transform_density(
'runtime',
groupby=['genres', 'countries'],
as_=['runtime', 'density'])
.mark_area(interpolate='monotone').encode(
x='runtime',
y='density:Q',
color='genres')
.facet('countries'))
We could instead scale it by the count, but again this is not that useful, as it is not as clear how to interpret this, compared to a histogram with discrete bins and a count in each bin.
(alt.Chart(boom_both)
.transform_density(
'runtime',
groupby=['genres', 'countries'],
as_=['runtime', 'density'],
counts=True)
.mark_area(interpolate='monotone').encode(
x='runtime',
y='density:Q',
color='genres')
.facet('countries'))
So in summary for densities, the important is the shape to see how the values are distributed, and possibly the size if you scale them, but just as a relative indicator versus other densities rather than relying too much on the exact values on the y-axis.
Here,
we could also use row and columns parameters to faceting
in order to separate the categorical variables further.
This is especially useful if we would have had a third categorical column,
so I made a true/false column for whether the movie had a high rating or not.
You will see that the the densities don’t work that well with this split,
but other marks would.
boom_both['vote_avg_over_4'] = boom_both['vote_average'] > 3
(alt.Chart(boom_both)
.transform_density(
'runtime',
groupby=['genres', 'countries', 'vote_avg_over_4'],
as_=['runtime', 'density'],
counts=True)
.mark_line().encode(
x='runtime',
y='density:Q',
color='genres')
.properties(height=100)
.facet(column='countries', row='vote_avg_over_4')
.resolve_scale(y='independent'))
In ggplot#
%%R
library(rjson)
library(tidyverse)
movies <- fromJSON(file = 'lec-movies.json') %>%
as_tibble() %>%
unnest(-c(countries, genres))
head(movies)
# A tibble: 6 x 11
id title runtime budget revenue genres countries vote_average vote_loved_it
<dbl> <chr> <dbl> <dbl> <dbl> <name> <named l> <dbl> <dbl>
1 12 Find… 100 9.40e7 9.40e8 <chr … <chr [1]> 3.86 0.322
2 22 Pira… 143 1.40e8 6.55e8 <chr … <chr [1]> 3.81 0.32
3 35 The … 87 7.50e7 5.27e8 <chr … <chr [1]> 3.44 0.155
4 58 Pira… 151 2.00e8 1.07e9 <chr … <chr [1]> 3.47 0.198
5 75 Mars… 106 7.00e7 1.01e8 <chr … <chr [1]> 2.96 0.086
6 117 The … 119 2.50e7 7.63e7 <chr … <chr [1]> 3.88 0.268
# … with 2 more variables: vote_count <dbl>, vote_std <dbl>
Let’s recall how to make a histogram.
%%R -w 500 -h 350
ggplot(movies) +
aes(x = runtime) +
geom_histogram(color = 'white')
R[write to console]: `stat_bin()` using `bins = 30`. Pick better value with `binwidth`.
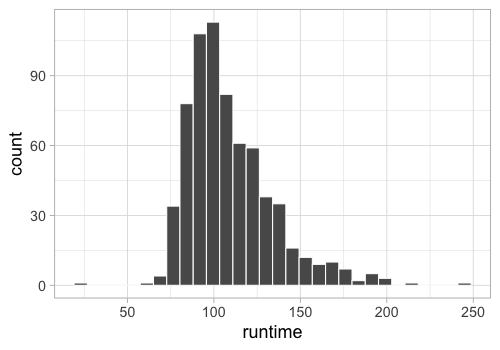
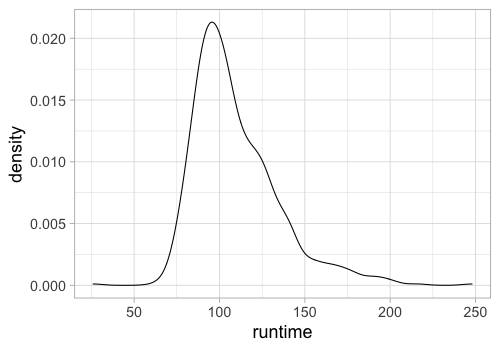
In ggplot,
there is a specific geom for densities
which does both the KDE calculation and plots a line.
%%R -w 500 -h 350
ggplot(movies) +
aes(x = runtime) +
geom_density()
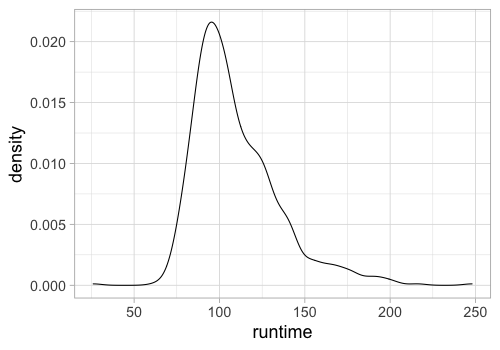
We can still control the parameters of the KDE calculation like in Altair, for example the bandwidth, how wide each kernel is (similar to histogram bin width).
%%R -w 500 -h 350
ggplot(movies) +
aes(x = runtime) +
geom_density(bw=5)
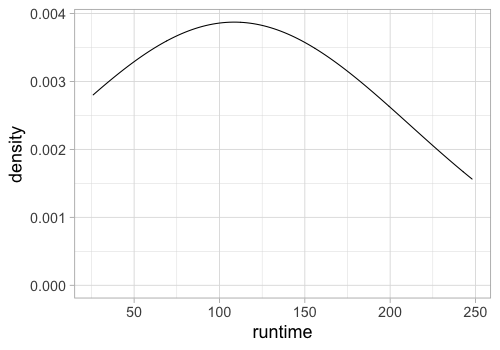
%%R -w 500 -h 350
ggplot(movies) +
aes(x = runtime) +
geom_density(bw=100)
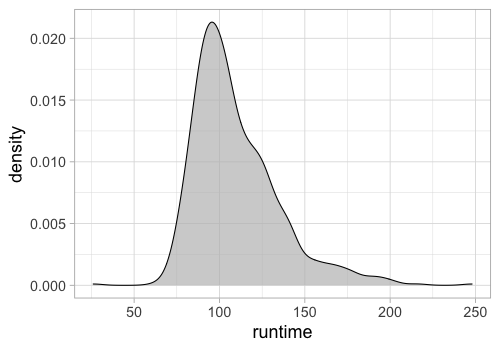
Filling the density can make it look a bit nicer.
%%R -w 500 -h 350
ggplot(movies) +
aes(x = runtime) +
geom_density(fill = 'grey', alpha = 0.7)
To color/fill by a variable,
we don’t need a separate groupby,
but can treat geom_density like any other geom,
which is convenient.
In dplyr,
a list can be unpacked via the unnest function.
%%R -w 500 -h 350
free_genres <- movies %>% unnest(genres)
ggplot(free_genres) +
aes(x = runtime,
fill = genres,
color = genres) +
geom_density(alpha = 0.6)
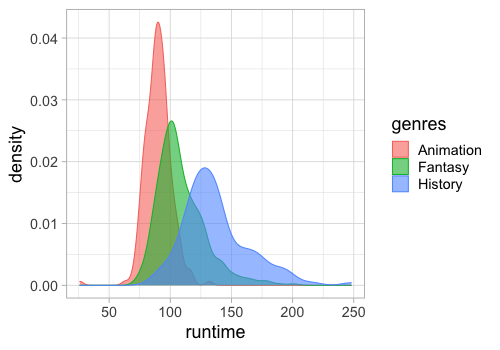
We need to unpack both genres and countries
if we want to use aesthetic mappings for both these columns.
%%R -w 700 -h 350
free_both <- free_genres %>%
unnest(countries)
ggplot(free_both) +
aes(x = runtime,
fill = genres,
color = genres) +
geom_density(alpha = 0.6) +
facet_wrap(~countries)
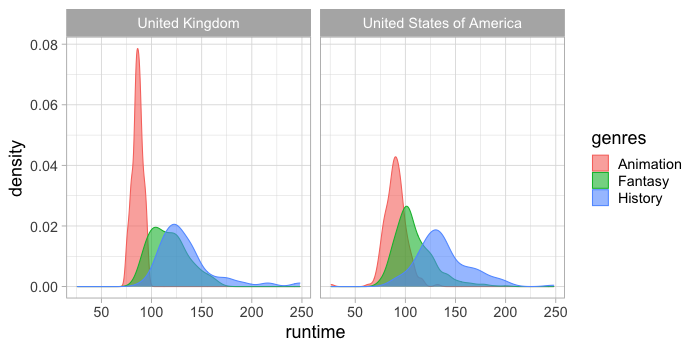
To map the rows and columns of the plot grid to variables in the data set,
we can use facet_grid instead of facet_wrap.
%%R -w 700 -h 350
ggplot(free_both) +
aes(x = runtime,
fill = genres,
color = genres) +
geom_density(alpha = 0.6) +
facet_grid(countries ~ genres)
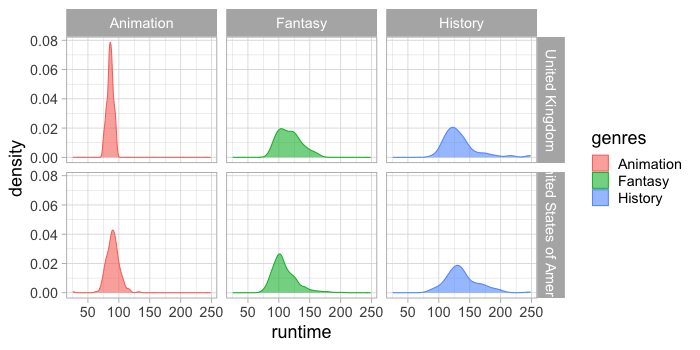
Comparing distributions for multiple categorical variables along the y-axis#
While it is possible to make violin plots and stripplots (categorical scatter plots) in Altair, these do currently not work with a categorical x/y axies, and you need to use faceting instead to display different categories, which gives us less flexibility. Therefore, we will primarily use boxplots when comparing multiple distributions with Altair.
(alt.Chart(boom_both)
.mark_boxplot().encode(
x='runtime',
y='genres',
color='genres')
.facet('countries', columns=1))
The size of the boxes can be made proportional to the count of observations in that group. We could also have used barplot for this, if we needed a more precise indication of the counts.
(alt.Chart(boom_both)
.mark_boxplot().encode(
x='runtime',
y='genres',
color='genres',
size='count()')
.facet('countries', columns=1))
Since I personally like seeing distributions, I also invented these 8-bit looking violins made out of square marks.
squareolins = (alt.Chart(boom_both)
.mark_square().encode(
x='runtime',
y='genres',
color='genres',
size='count()'
)
)
squareolins.facet('countries', columns=1)
We could add a mean dot. Below I recreate the chart since there is no good way to remove the size and color encodings that we had in the chart above (and we don’t want to color or resize the means). I could have done these plots in the opposite order and avoided having to code the entire chart twice, just changing the mark and the necessary encoding.
means = (
alt.Chart(boom_both)
.mark_circle(color='white').encode(
x='mean(runtime)',
y='genres'))
(squareolins + means).facet('countries', columns=1)
This is one thing I appreciate with Altair (and graphical grammars in general): understanding how to compose plots from individual elements, allows you some creativity in what you make versus using a pre-made plot via a set name (stripplot, violinplot, etc). You should of course be very careful with this because the common plots exist for good reason, they are statistically robust in many cases, and common enough that they are easier for people to interpret than your own creations in many cases.
In ggplot#
ggplot has a boxplot geom.
%%R -w 700 -h 350
ggplot(free_both) +
aes(x = runtime,
y = genres,
fill = genres) +
geom_boxplot() +
facet_wrap(~countries)
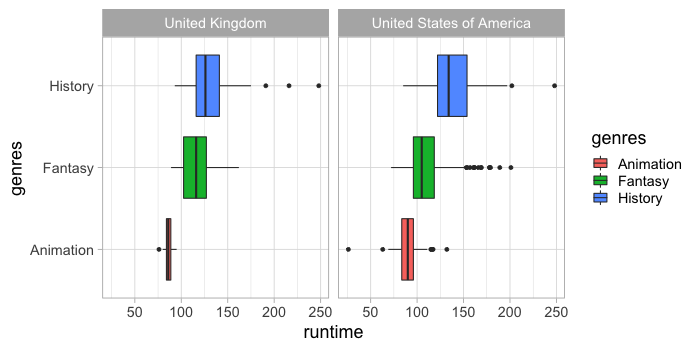
Which we can scale by the count of observations.
%%R -w 700 -h 350
ggplot(free_both) +
aes(x = runtime,
y = genres,
fill = genres) +
geom_boxplot(varwidth = TRUE) +
facet_wrap(~countries)
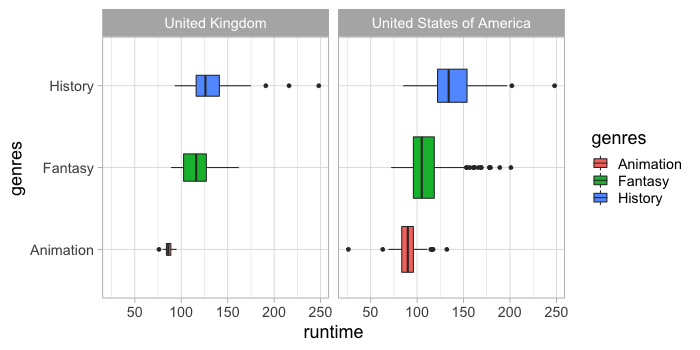
There is also a geom for creating violin plots which both calculates the density and then plots a line and an area.
%%R -w 700 -h 350
ggplot(free_both) +
aes(x = runtime,
y = genres,
fill = genres) +
geom_violin() +
facet_wrap(~countries)
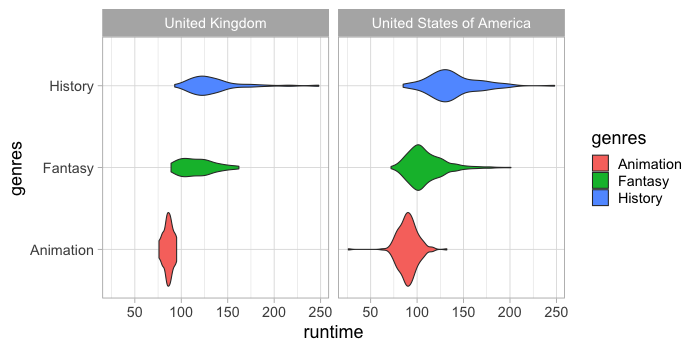
These can also be scaled by size.
%%R -w 700 -h 350
ggplot(free_both) +
aes(x = runtime,
y = genres,
fill = genres) +
geom_violin(scale = 'count') +
facet_wrap(~countries)
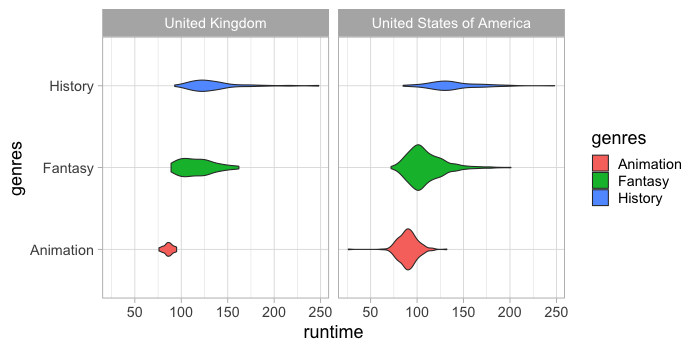
We can show the quantiles shown in the box plot also on the violin.
%%R -w 700 -h 350
ggplot(free_both) +
aes(x = runtime,
y = genres,
fill = genres) +
geom_violin(draw_quantiles = c(0.25, 0.5, 0.75)) +
facet_wrap(~countries)
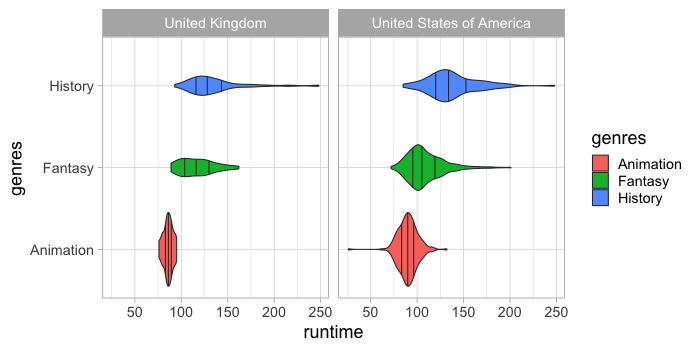
It is always a good idea to have a look at
where the individual data points are.
For this we can use a categorical scatter plot
where the dots are spread/jittered randomly on the non-value axis
so that they don’t all overlap via geom_jitter.
%%R -w 700 -h 350
ggplot(free_both) +
aes(x = runtime,
y = genres,
fill = genres) +
geom_violin() +
geom_jitter(height = 0.1, alpha = 0.2) +
facet_wrap(~countries)
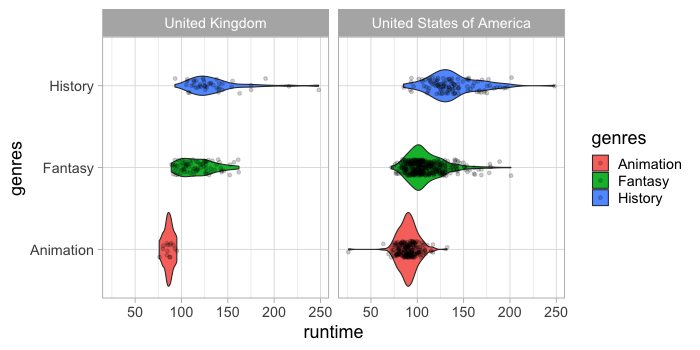
ggplot understands that if you color by a variable, it should create separate violins for each group on the same location of the categorical axis. In Altair, this would be a bit more cumbersome since we would need to use different facets.
%%R -w 500 -h 350
ggplot(free_both) +
aes(x = runtime,
y = genres,
fill = countries) +
geom_violin(draw_quantiles = c(0.25, 0.5, 0.75))
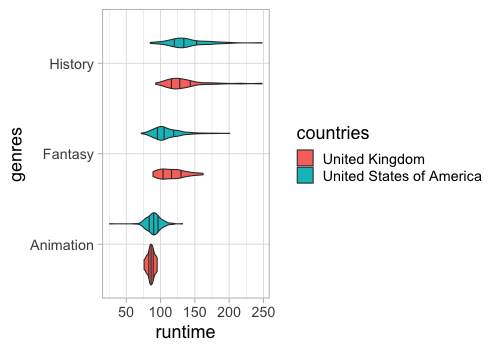
You could also use density lines in so called ridgeline plots to compare many distributions.
Repeating plots for different columns#
Repeating columns on a single axis#
Previously we have made subplots via faceting, which creates one subplot per unique value in a categorical column and displays the same numerical columns in all the subplots/facets. This view of multiple subsets in the data is often called a trellis plot or plot of small multiples. Here, we will see how we can create subplots that each display all the data points, but is repeated for different columns in the data.
We specify which columns we want to use via the .repeat method,
and where we want to use them via alt.repeat.
For this plot,
we keep the y-axis constant,
and repeat the plot for different x-axis columns.
boom_both.columns
Index(['id', 'title', 'runtime', 'budget', 'revenue', 'genres', 'countries',
'vote_average', 'vote_loved_it', 'vote_count', 'vote_std'],
dtype='object')
(alt.Chart(boom_both)
.mark_boxplot().encode(
alt.X('genres'),
alt.Y(alt.repeat(), type='quantitative'),
color='genres',
# size='count()'
)
.repeat(['runtime', 'revenue','vote_average', 'vote_count']))
This is very powerful for quick data exploration, and uses a consistent grammar which gives you lots of flexibility for customization instead of having a specific function that made only this type of plot (which is common elsewhere).
You can even combine facet and repeat but note that this does not work with all marks yet, although for boxplots it is fine.
(alt.Chart(boom_both).mark_boxplot().encode(
alt.X(alt.repeat(), type='quantitative', scale=alt.Scale(zero=False)),
alt.Y('genres', title=''), # Removing labels to make the chart less busy
color='genres')
.properties(height=100, width=250)
.facet(row='countries')
.repeat(repeat=['runtime', 'revenue']))
Repeating columns on both axes#
To efficiently repeat over both the axis,
we can use the column and row parameter to repeat.
These work similarly as they do for facet,
distributing the list of data frame variables
over only one axis,
which we specify with alt.repeat to the x and y axis.
(alt.Chart(boom_both)
.mark_boxplot().encode(
alt.X(alt.repeat('row'), type='quantitative'),
alt.Y(alt.repeat('column'), type='nominal', title=''),
alt.Color(alt.repeat('column'), type='nominal', title='Genre or Country'))
.properties(height=100, width=250)
.repeat(column=['genres', 'countries'],
row=['runtime', 'revenue']))
When we don’t give any named parameters to repeat and alt.repeat,
they use the default,
which is repeat and then you wrap with columns=2 if you want more than one row
as we did above.
We could also use this technique to create a what is usually called a scatter plot matrix (or pairplot), where we repeat numerical columns on both axes to investigate their pairwise relationships.
(alt.Chart(boom_both)
.mark_point().encode(
alt.X(alt.repeat('row'), type='quantitative'),
alt.Y(alt.repeat('column'), type='quantitative'))
.properties(width=200, height=200)
.repeat(column=['runtime', 'revenue'], row=['runtime', 'revenue']))
When there are many plots, it can be hard to see, so as long as this is just for our own exploratory analysis, it can be a good idea to hide the labels or make them much smaller (possible toggling back on and off if we need to check an axis range). To avoid saturation (overplotting) we can make the dots smaller and a bit transparent.
(alt.Chart(boom_both)
.mark_point(size=2, opacity=0.2).encode(
alt.X(alt.repeat('row'), type='quantitative'),
alt.Y(alt.repeat('column'), type='quantitative'))
.properties(width=200, height=200)
.repeat(column=['runtime', 'revenue'], row=['runtime', 'revenue'])
.configure_axis(labels=False))
It is still a bit hard to see exactly where most of the dots are, so we could create a binned count plot instead for a more accurate representation.
# could also use alt.axis
(alt.Chart(boom_both)
.mark_rect().encode(
alt.X(alt.repeat('row'), type='quantitative', bin=alt.Bin(maxbins=20)),
alt.Y(alt.repeat('column'), type='quantitative', bin=alt.Bin(maxbins=20)),
alt.Color('count()'))
.properties(width=200, height=200)
.repeat(column=['runtime', 'revenue'], row=['runtime', 'revenue'])
.configure_axis(labels=False))
In ggplot#
There is not “repeat” function in ggplot, so we would first need to pivot all data frame variables into the same column and then use faceting on this new column name.
%%R -w 800 -h 550
movies %>%
select_if(is.numeric) %>%
pivot_longer(everything()) %>%
ggplot(aes(x = value)) +
geom_density(fill = 'grey') +
facet_wrap(~name, scales = 'free')
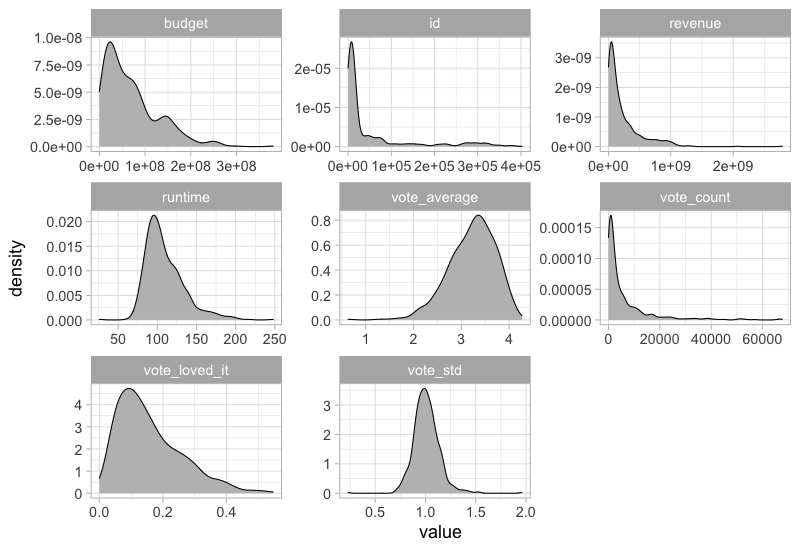
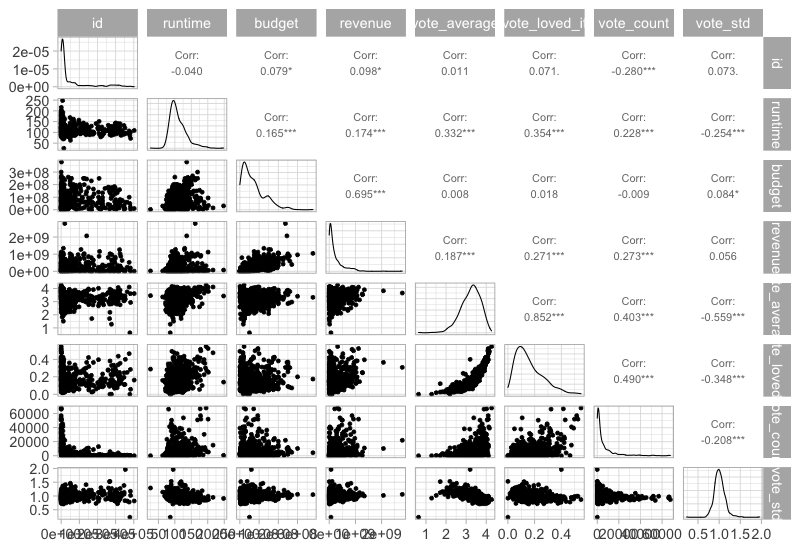
This would not work if both axes are numerical, but luckiy there is an extension packagge for ggplot called GGally, which can be used here. It also plots the density curves on the diagonal and the correlations on top.
To install it, you need to run install.packages(‘GGally’)
%%R -w 800 -h 550
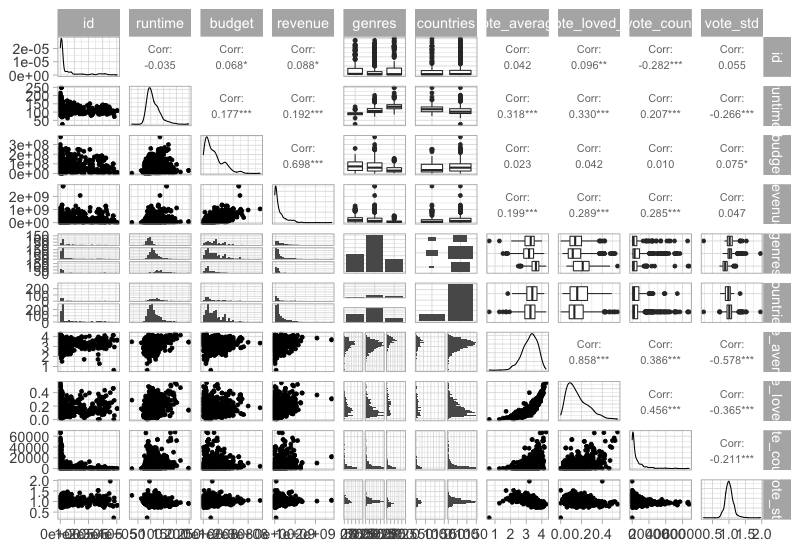
GGally::ggpairs(movies %>% select_if(is.numeric), progress = FALSE)
This function can also show info on categorical variables.
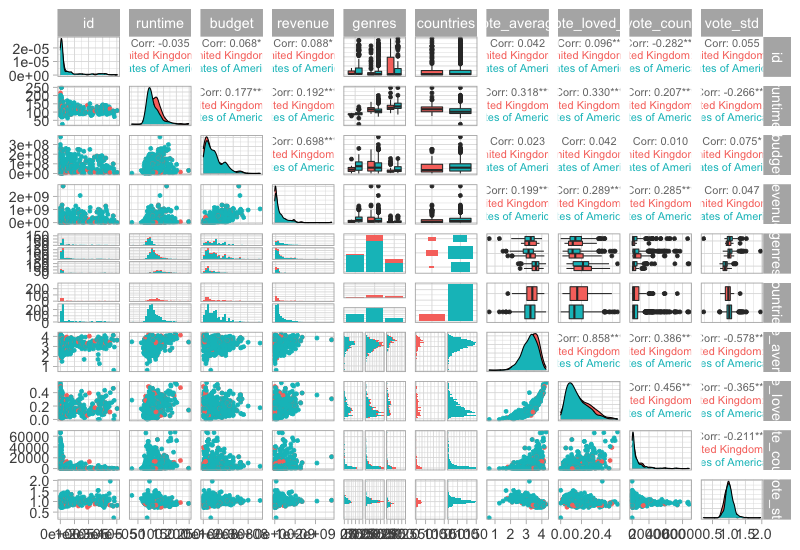
%%R -w 800 -h 550
GGally::ggpairs(free_both %>% select(-title), progress=FALSE)
R[write to console]: `stat_bin()` using `bins = 30`. Pick better value with `binwidth`.
R[write to console]: `stat_bin()` using `bins = 30`. Pick better value with `binwidth`.
R[write to console]: `stat_bin()` using `bins = 30`. Pick better value with `binwidth`.
R[write to console]: `stat_bin()` using `bins = 30`. Pick better value with `binwidth`.
R[write to console]: `stat_bin()` using `bins = 30`. Pick better value with `binwidth`.
R[write to console]: `stat_bin()` using `bins = 30`. Pick better value with `binwidth`.
R[write to console]: `stat_bin()` using `bins = 30`. Pick better value with `binwidth`.
R[write to console]: `stat_bin()` using `bins = 30`. Pick better value with `binwidth`.
R[write to console]: `stat_bin()` using `bins = 30`. Pick better value with `binwidth`.
R[write to console]: `stat_bin()` using `bins = 30`. Pick better value with `binwidth`.
R[write to console]: `stat_bin()` using `bins = 30`. Pick better value with `binwidth`.
R[write to console]: `stat_bin()` using `bins = 30`. Pick better value with `binwidth`.
R[write to console]: `stat_bin()` using `bins = 30`. Pick better value with `binwidth`.
R[write to console]: `stat_bin()` using `bins = 30`. Pick better value with `binwidth`.
R[write to console]: `stat_bin()` using `bins = 30`. Pick better value with `binwidth`.
R[write to console]: `stat_bin()` using `bins = 30`. Pick better value with `binwidth`.
And color by another categorical.
%%R -w 800 -h 550
GGally::ggpairs(free_both %>% select(-title), aes(color = countries), progress=FALSE)
R[write to console]: `stat_bin()` using `bins = 30`. Pick better value with `binwidth`.
R[write to console]: `stat_bin()` using `bins = 30`. Pick better value with `binwidth`.
R[write to console]: `stat_bin()` using `bins = 30`. Pick better value with `binwidth`.
R[write to console]: `stat_bin()` using `bins = 30`. Pick better value with `binwidth`.
R[write to console]: `stat_bin()` using `bins = 30`. Pick better value with `binwidth`.
R[write to console]: `stat_bin()` using `bins = 30`. Pick better value with `binwidth`.
R[write to console]: `stat_bin()` using `bins = 30`. Pick better value with `binwidth`.
R[write to console]: `stat_bin()` using `bins = 30`. Pick better value with `binwidth`.
R[write to console]: `stat_bin()` using `bins = 30`. Pick better value with `binwidth`.
R[write to console]: `stat_bin()` using `bins = 30`. Pick better value with `binwidth`.
R[write to console]: `stat_bin()` using `bins = 30`. Pick better value with `binwidth`.
R[write to console]: `stat_bin()` using `bins = 30`. Pick better value with `binwidth`.
R[write to console]: `stat_bin()` using `bins = 30`. Pick better value with `binwidth`.
R[write to console]: `stat_bin()` using `bins = 30`. Pick better value with `binwidth`.
R[write to console]: `stat_bin()` using `bins = 30`. Pick better value with `binwidth`.
R[write to console]: `stat_bin()` using `bins = 30`. Pick better value with `binwidth`.
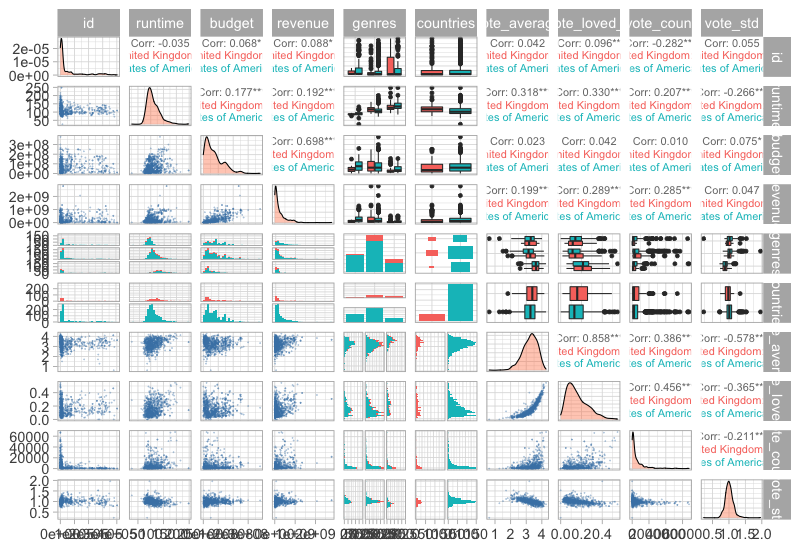
Customizing these plots are possible but bit cumbersome, this blog post has some good examples.
%%R -w 800 -h 550
GGally::ggpairs(
free_both %>% select(-title),
aes(color = countries),
progress = FALSE,
lower = list(continuous = GGally::wrap('points', alpha = 0.3, size=0.1, color = 'steelblue')),
diag = list(continuous = GGally::wrap('densityDiag', fill = 'coral', alpha = 0.4)))
R[write to console]: `stat_bin()` using `bins = 30`. Pick better value with `binwidth`.
R[write to console]: `stat_bin()` using `bins = 30`. Pick better value with `binwidth`.
R[write to console]: `stat_bin()` using `bins = 30`. Pick better value with `binwidth`.
R[write to console]: `stat_bin()` using `bins = 30`. Pick better value with `binwidth`.
R[write to console]: `stat_bin()` using `bins = 30`. Pick better value with `binwidth`.
R[write to console]: `stat_bin()` using `bins = 30`. Pick better value with `binwidth`.
R[write to console]: `stat_bin()` using `bins = 30`. Pick better value with `binwidth`.
R[write to console]: `stat_bin()` using `bins = 30`. Pick better value with `binwidth`.
R[write to console]: `stat_bin()` using `bins = 30`. Pick better value with `binwidth`.
R[write to console]: `stat_bin()` using `bins = 30`. Pick better value with `binwidth`.
R[write to console]: `stat_bin()` using `bins = 30`. Pick better value with `binwidth`.
R[write to console]: `stat_bin()` using `bins = 30`. Pick better value with `binwidth`.
R[write to console]: `stat_bin()` using `bins = 30`. Pick better value with `binwidth`.
R[write to console]: `stat_bin()` using `bins = 30`. Pick better value with `binwidth`.
R[write to console]: `stat_bin()` using `bins = 30`. Pick better value with `binwidth`.
R[write to console]: `stat_bin()` using `bins = 30`. Pick better value with `binwidth`.
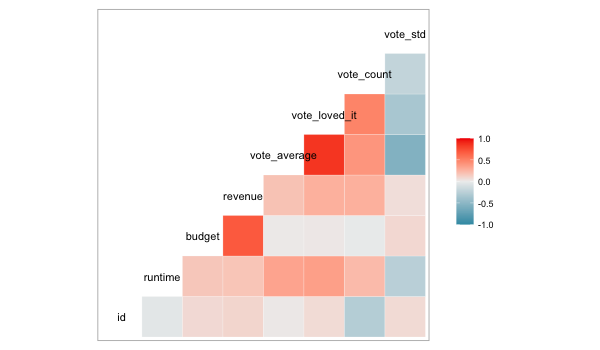
Correlation plots#
A good complement to a scatter plot matrix is a correlation plot which helps formalize the correlation between numerical variables. Using “spearman” correlation instead of “pearson” allows us to detect non-linear relationships better.
corr_df = (
movies
.select_dtypes('number')
.corr('spearman')
.abs() # Use abs for negative correlation to stand out
.stack() # Get df into long format for altair
.reset_index(name='corr')) # Name the index that is reset to avoid name collision
alt.Chart(corr_df).mark_square().encode(
x='level_0',
y='level_1',
size='corr',
color='corr')
With some effort, we can make it look nicer.
corr_df = movies.select_dtypes('number').corr('spearman').stack().reset_index(name='corr')
corr_df.loc[corr_df['corr'] == 1, 'corr'] = 0
corr_df['abs'] = corr_df['corr'].abs()
alt.Chart(corr_df).mark_square().encode(
x='level_0',
y='level_1',
size='abs',
color=alt.Color('corr', scale=alt.Scale(scheme='blueorange', domain=(-1, 1))))
The domain argument sets the extent of the colorscale (from a perfect negative to a perfect positive correlation), we will talk more about colorscale later in the course.
In ggplot#
We could do the separate calculation in ggplot as well, but there is also a special function in GGally, which does the computation and visualizes it as a heatmap.
%%R -w 600 -h 350
GGally::ggcorr(movies)
Counting combinations of categorical groups#
Counting categoricals is helpful to get and overview of where most observations lie. Often the size and color can be used for this, similar to the correlation plot.
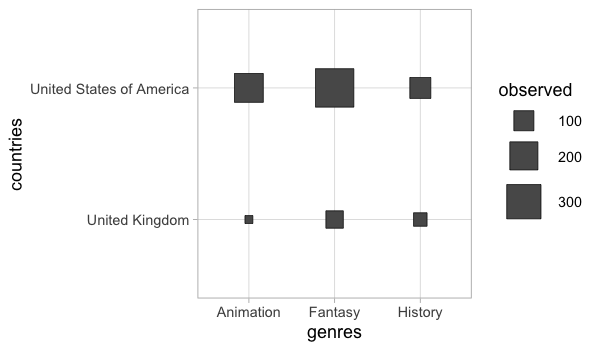
alt.Chart(boom_both).mark_square().encode(
x='genres',
y='countries',
color='count()',
size='count()')
Or a heatmap could be created (we could have done this for the correlation plot as well).
alt.Chart(boom_both).mark_rect().encode(
x='genres',
y='countries',
color='count()')
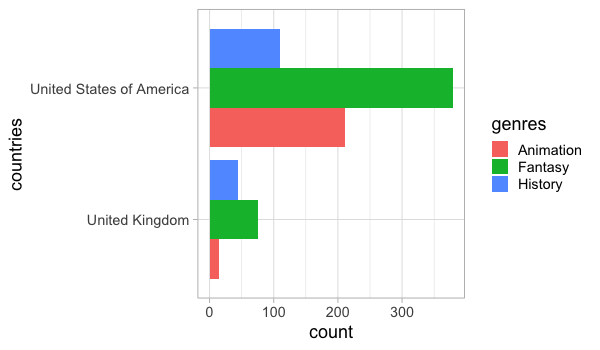
For more precise counts, we could use a faceted bar chart.
alt.Chart(boom_both).mark_bar().encode(
x='count()',
y='genres',
color='genres').facet(row='countries')
In ggplot#
GGally has a similar plot for counting categories.
%%R -w 600 -h 350
GGally::ggally_cross(free_both, aes(x = genres, y = countries))
A barplot of counts could be made directly in ggplot.
%%R -w 600 -h 350
ggplot(free_both) +
aes(y = countries,
fill = genres) +
geom_bar(stat = 'count', position = 'dodge')
Lecture learning goals#
By the end of the lecture you will be able to:
Visualize distributions.
Understand how different distribution plots are made and their pros and cons.
Select an appropriate distribution plot for the situation.
Grasp EDA on a conceptual levels both for numerical and categorical variables.
Create density plots to compare a few distributions.
Create boxplots and violin plot to compare many distributions.
Use repeated plot grids to investigate multiple data frame columns in the same plot.
Visualize correlations and counts of categorical variables.